Ylang: 适用于 eBPF、Stap+、GDB 等框架的通用语言(第一集,全四集)
这篇文章是“Y 语言:适用于 eBPF、Stap+、GDB 等的通用语言”系列的第一集。其他集详见第二集,第三集和第四集。
Y 或 Ylang 是适用于多种动态追踪框架和工具链的一种通用的动态追踪语言。该语言是 OpenResty Inc. 开发的 OpenResty XRay 平台的重要组成部分。
什么是动态追踪
动态追踪是一组技术的统称。它可以对运行中的软件系统进行分析并帮助软件排除故障。这个过程是以安全、实时、事后、高效和非侵入的方式进行的。
许多类似于 APM 的技术都声称是非侵入性的,实际上它们仍然需要目标进程和应用程序的专门配合。例如,它们可能需要加载特殊的模块和库,向目标进程注入新的代码,或者要求它们通过 API 调用或日志文件来输出数据。
我曾经写过一篇文章详细介绍动态追踪,标题是“动态追踪技术漫谈”。欢迎您去看看。
为什么命名为 “Y”
您可能想知道为什么我把这门语言起名为 Y。这是我还在 Cloudflare 工作的时候,公司的首席执行官 Matthew Prince 给起的名字。他说这是我名字的第一个字母,Yichun,更重要的是,它与 “为什么(why)” 这个词同音。动态追踪语言通常旨在回答以“为什么”开头的复杂问题。那个时候,Ylang 还是一个非常模糊的想法。几年之后成立 OpenResty 公司的时候我选择了保留这个名字,感谢 Matthew。
入门
Hello World 的例子
让我们用 Y 语言实现一个经典的 “hello world” 的例子:
$ run-y -e '_probe _oneshot { printf("Hello, world!\n"); }'
Start tracing...
Hello, world!
run-y 工具来自于 OpenResty XRay 包。
这里的 _probe 关键字为特殊探测点 _oneshot 定义了一个新的探针处理程序,在分析器启动的时候被触发。而当 _oneshot 探针执行完毕后,分析器会立即退出。printf() 函数的作用等同于标准 C 语言的 printf() 函数。
指定目标进程
使用特殊的 _oneshot 探针是尝试 Y 语言特性的一个好方法。我们将在本系列文章的后面看到更多的例子。一般来说我们会使用其他种类的探针来进行真实的分析,如函数探针、系统调用探针、进程调度器探针、CPU 分析器探针等等。在这些情况下,我们可以通过 PID 指定一个运行中的目标进程,如
# 假设目标进程的 PID 为 5786
run-y -p 5786 my-tool.y
也可以指定一个进程组 ID(PGID),如
# 假设目标进程组有相同的进程组 ID,14927
run-y -p -14927 my-tool.y
如果一个实时进程的 PID 等于指定的进程组 ID,我们的工具链将自动从该进程中获得真正的进程组 ID。指定 Nginx 主进程来跟踪整个 Nginx 进程组是很方便的,其中主进程的 PID 与进程组 ID 并不 相同(当启用守护进程模式的时候)。
如果我们想从程序启动的时候就开始追踪它的整个生命周期,我们应该在用 run-y 工具启动进程的时候使用 c 选项,例如
run-y -c '/usr/bin/perl -e1' my-tool.y
这里我们追踪的是 perl 命令的整个生命周期。这可以确保我们不会错过早期的探针,比如在 main 函数入口处的探针。
当没有指定 -p 和 -c 选项时,run-y 工具默认会追踪整个操作系统。
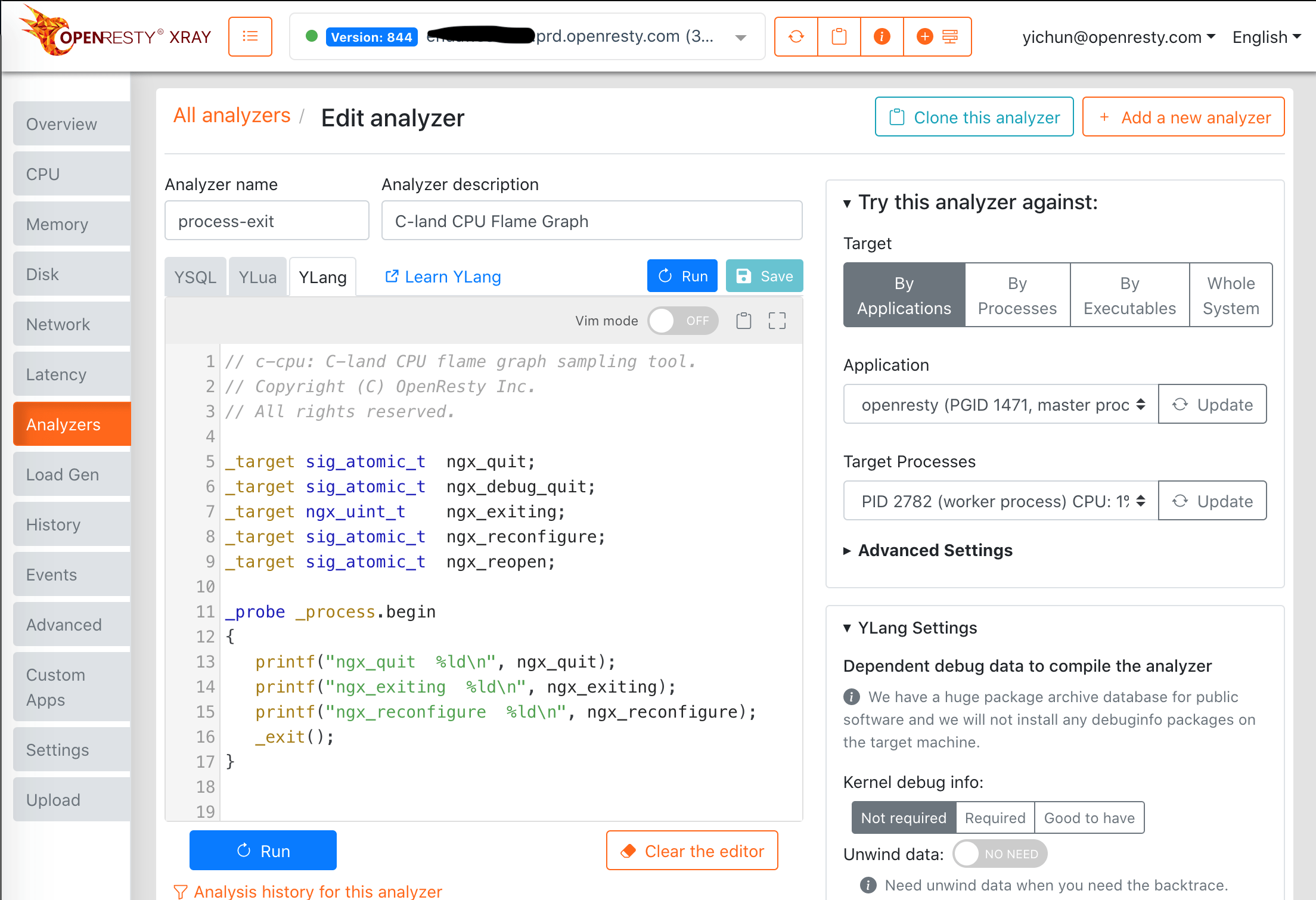
Web 控制台
也可以使用 OpenResty XRay 的 Web 控制台来编辑和运行 Ylang 程序或分析器。下方是该控制台的截图。
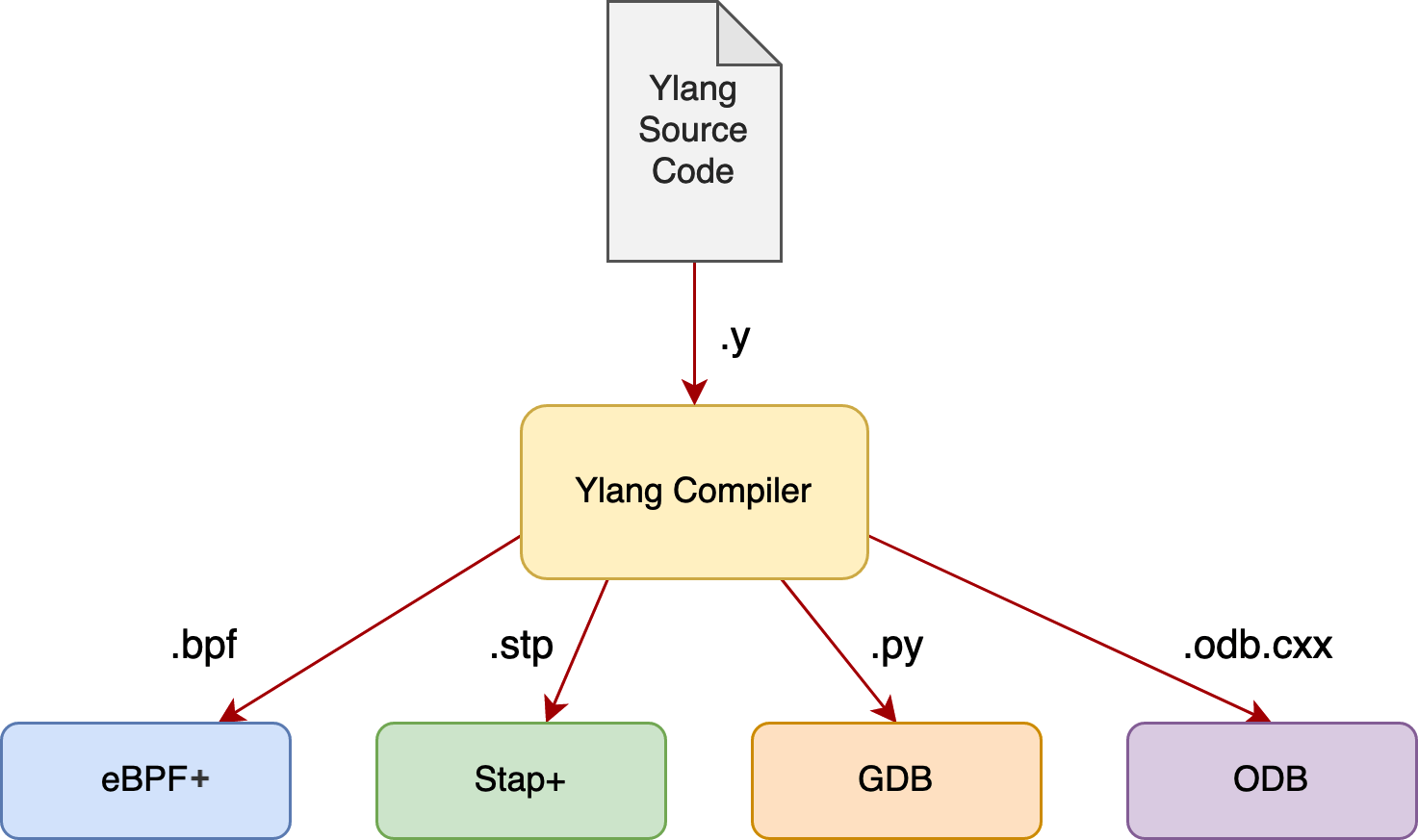
各种后端和运行时
目前支持以下后端:
-
eBPF+(我们对 Linux 的开源 eBPF 虚拟机和工具链进行了极大的改进)、
-
Stap+(我们对 Red Hat 公司的开源 SystemTap 进行了大量优化)、
-
GDB (GNU 项目调试器)及其 Python 扩展,以及
-
ODB(OpenResty 调试器,类似于 GDB,但要轻量很多)
为什么我们需要这么多不同的调试框架呢?这是因为每一种技术都有其优势和劣势,因此有各种不同的使用场景。现在让我们逐个来分析它们:
-
eBPF 是一个相对较新的技术,所以它通常需要较新的 Linux 内核。但是它编译和加载工具的速度比诸如 SystemTap(有着默认的内核运行时)这样的框架要快得多。
-
Stap+ 与 SystemTap 类似。两者都能在很多内核版本上工作,甚至是 CentOS 7 的 3.10 内核(但不要误以为这里指的是标准的 3.10 内核,Red Hat 已经从较新的内核上回传了大量补丁)。
-
GDB 是唯一可以分析 core dump 文件(来自崩溃的进程)的后端。但是,它仍然可以使用断点来模拟函数探测和动态追踪,只是速度很慢,成本很高。
-
ODB 与 GDB 相似,但没有 GDB 那样的历史包袱。它仍然是一个纯粹的 user-land 跟踪框架,但比 GDB 快了好几个数量级。对于一些有缺陷的 Intel Xeon CPU,它们可能会在完全有效的内存访问请求中产生大量的页面错误。在这种情况下,基于内核的动态追踪,如 eBPF 和 Stap+ 往往不能在禁用页面错误的情况下读取目标进程的内存。因此 ODB 是这类芯片上的唯一选择。
我们计划支持更多的后端,比如 LLVM 的 LLDB(通过其 Python 扩展 API,就像 GDB)和用于分析崩溃的 Linux 内核的 core dump(kdump)文件的工具。
通常情况下,OpenResty XRay 会自动选择或重新选择适合当前用例和环境的后端。但用户也可以明确地选择一个特定的运行时。
为什么要使用一个统一的前端语言
Ylang 是一个可以应用于所有调试和动态追踪框架的统一的前端语言。它可以避免我们为上述不同的应用场景编写大量的重复代码。一个单一的 Ylang 工具可以立即在各种技术和框架中使用,实现在线跟踪、core dump 文件分析等多种目的。Ylang 编译器可以确保在不同的后端中精确保留语义,从而节省大量的人力。
Y 语言的语法
Ylang 扩展了 C 语言的一个庞大的子集,为动态追踪提供了语法和原语。C 程序员应该会觉得它非常容易使用。Ylang试图能与 C 语言(甚至是 GNU C的一部分)在极细微的程度上达到真正地兼容。事实上,我们可以把许多真实的 C 代码片段当作完全有效的 Ylang 代码,而无需进行任何编辑。毕竟,从 MySQL 和 PostgreSQL 这样的数据库到 CPython、Ruby、Perl 和 PHP 等高级语言解释器和编译器,许多开源程序和库都是用 C 语言编写的。甚至 Linux 内核也是用 C 语言编写的。C++ 代码也可以通过 C++-to-C 编译器转换为 C 语言。因此,所有那些 C++ 开源项目,如 Chromium、Qt、JVM 和 NodeJS,也可以成为新的 Ylang 分析器和工具的代码来源。
为什么使用与目标软件相同的语言如此重要呢?因为每次我们想为目标应用程序创建一个新的分析器时,编写这种工具最繁琐和费力的部分就是绕过目标的数据结构。目标应用程序本身又必须使用这些数据结构,所以最自然的方式是直接借用它们的那些成熟代码来收集我们需要的信息。简单的复制&粘贴极大地降低了创建新的动态追踪工具和分析器的成本。
除了 C 风格的 Ylang 之外,OpenResty XRay还提供了针对 Ylang 的其他语言的编译器,如 Lua 语法的 YLua 和 SQL 语法的 YSql。我们将在后续的文章中介绍这些语言。我们也计划支持更多的语言,比如 Python、Ruby、Java、Rust、Go 等语言的 Y 变种。
其他工具链使用的语言
Stap/D/Bpftrace: 与 C 类似但不是 C
其他开源框架,如 DTrace、SystemTap 和 Bpftrace(目标是 eBPF)都引入了自己的脚本语言。不幸的是,这些语言只是看起来像 C 语言,而从来没有想过要与 C 语言真正地兼容。所以简单地复制&粘贴目标应用程序中的 C 代码是行不通的。要把代码移植到这些框架的脚本语言上,是很费时费力的。如果工具的逻辑复杂,测试被移植工具的正确性和调试其中的错误也很不容易。
对于真正的 C 程序员来说,它甚至可能看起来也不像 C。我们用 SystemTap 的脚本语言举个例子。看看下面的 Ylang 代码片段:
_target long *my_var;
int get_val(void) {
return *(int *) my_var;
}
除了特殊的 _target 关键字,这个片段看起来是完全就是 C 程序。_target 关键字是 Ylang 引入的一个扩展。这个关键字代表声明的符号来自目标进程(或 tracee 空间)。如果我们想把这段代码变成 SystemTap 的脚本,它将会是这样的:
function get_val() {
return @cast(@var("my_var", "/path/to/target/exe/file"), "int", "/path/to/target/exe/file")[0];
}
这看起来很不一样,更加冗长。我们必须在代码中硬编码可执行文件的路径,或者通过宏来传递它。
这些脚本语言最重要的痛点是缺少一个 C 风格的类型系统。通常只能用一个有符号的 long int 类型来表示整数。您必须自己模拟所有细微的 C 语言整数类型转换和算术语义,这非常烦人,而且容易出错。
您可以在 GitHub 的这些公共资源库中查看我们手写的一些真实的复杂的 SystemTap 脚本,openresty-systemtap-toolkit,以及 stapxx。这样的脚本语言通常用处不大,我们必须得写一个 Perl wrapper 来把它们变成更有用的命令行工具。有些人喜欢用其他更强大的脚本语言来写这种 wrapper,比如 Python 和 Bash。
然而,通过 Ylang,用户只需使用一种与 C 语言兼容的语言,再也不需要其他脚本语言的丑陋 wrapper 了。
eBPF: 是 C 但是比 C 更难
官方的 eBPF 工具链(包括 BCC)通常通过 LLVM 和 Clang 使用自然 C 语言。遗憾的是,这种 C 语言也有许多严重的限制,仅举几例:
- 用户自定义的函数最多只能接受 5 个参数1。
- 因为有 Linux 内核 eBPF 验证器中的静态代码分析器,流程控制语句有诸多限制。这个验证器也为大型 eBPF 程序引入了很高的 CPU 开销。向后跳转和普通的循环通常是禁用的。
- 不允许通过函数返回值和参数传递复合类型的值(如 struct 和 union 值)2。
- 暂时还不支持跨
.data,.rodata,.bss和其他类似数据段的数据引用的重新定位3 。 - 没有或很少有对目标进程中定义的类型的内置支持。所以用户通常要自己手动声明所有的类型。
- 没有内置的 VMA 跟踪器4支持,所以用户必须自己计算虚拟内存地址,这非常繁琐,而且容易出错。
- 内置的 stack unwinder 从不使用目标进程的 unwinding tables 或 DWARF 数据,因此在编译目标进程时会依赖于禁用帧指针寄存器。
- 除了 BPF Map 和基于堆栈的自动变量,运行时缺乏任何内置的内存分配和管理机制。即使是处理最普通的 C 字符串,也是非常痛苦的。
- 在编译器工具链和 BPF 指令集中都没有带符号的除法操作支持5。
- 不支持浮点数6。
我就说到这里吧,类似的限制还有很多。我们经常这样开玩笑,大多数人认为编写内核 C 代码非常困难,实际上编写稍微复杂一点的 eBPF C 代码比编写内核 C 代码要难得多。幸运的是,Ylang 使用的 eBPF+ 实现几乎解决了上面列出的所有问题,Ylang 编译器可以为我们自动编写这种复杂的 eBPF C 代码。我们可以写出自然、干净的 C 语言代码,完全不用考虑那些烦人的细节。
尽管如此,标准的 eBPF 工具链还需要一个用像 Python 和 C 这样的语言编写的独立的 user-land 程序(大多数人使用 Python)。这比用 SystemTap 的脚本语言编写的工具的 shell wrapper 更加麻烦。Ylang 编译器也能自动生成这种 user-land 程序。(Ylang 可以为这类程序生成经过优化的 C 代码,因为 Python 既臃肿又缓慢)
GDB/LLDB: 根本不像 C
使用一种与 C 语言语法截然不同的语言来编写分析 C/C++ 应用程序的工具只会更难。比如 GDB 和 LLDB,GDB 提供了 Python 和 Scheme 语言来编写新的扩展。而 LLVM 提供了 Python。使用 Python 来跟踪 Python 应用程序您可能感觉很自然,事实并非如此!这样的 GDB Python 代码总是用来分析用低级语言如 C 写的东西!这导致了即便是简单的 C 逻辑,也会产生可怕的 Python 代码。例如,来看看下面这段简单的 C 语句:
int a = *(int *) my_var;
其中 my_var 是目标进程中的一个变量。把它变成一个 GDB Python 代码段,是这样的:
sym_my_var = gdb.lookup_global_symbol("my_var")
if sym_my_var is None:
sym_my_var, _ = gdb.lookup_symbol("my_var")
a = sym_my_var.value().cast(gdb.lookup_type("int").pointer()).dereference()
在 Ylang 中,您可以写出前一种代码的格式,并像这样声明目标变量 my_var:
_target long *my_var;
注意 _target 关键字是 Ylang 的一个新扩展,表示目标软件中的一个符号。
在 GDB Python 中,当复杂性积累到一定程度,情况很快会变得更糟。来看一个手写的 GDB Python 脚本中的一个糟糕的例子。这是最可怕的噩梦。
幸运的是,即使是 Ylang 编译器也不必生成上述冗长且缓慢的 Python 代码。它可以绕过繁琐的 gdb.Value 对象,生成更紧凑的代码,这有以下好处:
- 由此产生的 Python 代码在运行时明显更快(有时会快几倍)。
- 由此产生的代码也小得多,因为它更加紧凑。
- 由此产生的代码不再要求 DWARF 数据存在于目标环境中(因此,我们称之为无 DWARF)。
尽管如此,Ylang 编译器也可以生成这种慢速形式的代码,这种代码只有人类用户才会使用,用来比较两种不同的形式。
未完待续
这篇文章已经很长了。从第二集开始,我们将更加关注 Ylang 的特性和例子。
关于作者
章亦春是开源 OpenResty® 项目创始人兼 OpenResty Inc. 公司 CEO 和创始人。
章亦春(Github ID: agentzh),生于中国江苏,现定居美国湾区。他是中国早期开源技术和文化的倡导者和领军人物,曾供职于多家国际知名的高科技企业,如 Cloudflare、雅虎、阿里巴巴, 是 “边缘计算“、”动态追踪 “和 “机器编程 “的先驱,拥有超过 22 年的编程及 16 年的开源经验。作为拥有超过 4000 万全球域名用户的开源项目的领导者。他基于其 OpenResty® 开源项目打造的高科技企业 OpenResty Inc. 位于美国硅谷中心。其主打的两个产品 OpenResty XRay(利用动态追踪技术的非侵入式的故障剖析和排除工具)和 OpenResty Edge(最适合微服务和分布式流量的全能型网关软件),广受全球众多上市及大型企业青睐。在 OpenResty 以外,章亦春为多个开源项目贡献了累计超过百万行代码,其中包括,Linux 内核、Nginx、LuaJIT、GDB、SystemTap、LLVM、Perl 等,并编写过 60 多个开源软件库。
关注我们
如果您喜欢本文,欢迎关注我们 OpenResty Inc. 公司的博客网站 。也欢迎扫码关注我们的微信公众号:

翻译
我们提供了英文版原文和中译版(本文)。我们也欢迎读者提供其他语言的翻译版本,只要是全文翻译不带省略,我们都将会考虑采用,非常感谢!
-
这种错过的重定位可能导致运行时出现 NULL 指针 deference,这可能导致 kernel panic。 ↩︎
-
eBPF C 开发人员应该熟悉 Clang 编译器的错误 “不支持带有 VarArgs 或 StructRet 的函数”。 ↩︎
-
VMA 跟踪器将目标进程中的相对地址映射到绝对虚拟内存地址,反之亦然。 ↩︎
-
eBPF 的 C 语言开发人员应该对 Clang 编译器的错误并不陌生,比如 “不支持 DAG 的带符号的除法” 和 “后端错误:无法选择:0x55ba75efac30: i64 = sdiv”。 ↩︎
-
许多动态追踪框架不支持浮点数。唯一的例外是 SystemTap(它最近添加了这个功能)、GDB Python 和 Solaris 上的 DTrace(其他操作系统上的 DTrace 端口仍然缺乏这个功能)。 ↩︎
相关文章
OpenResty XRay Sep 20, 2023

OpenResty XRay Aug 22, 2023

OpenResty XRay Aug 21, 2023

OpenResty XRay Nov 24, 2023
")
OpenResty XRay Aug 6, 2023
")









")
")
")



")
")