Ylang:適用於 eBPF、Stap+、GDB 等框架的通用語言(第四集,全四集)
這篇文章是“Y 語言:適用於 eBPF、Stap+、GDB 等的通用語言”系列的第四集。其他集詳見第一集、 第二集和第三集。
透明的跨容器追蹤
Y 語言支援跨容器邊界的透明追蹤。它可以像常規的目標程序一樣追蹤 Docker 和 Kubernetes 容器。使用者可以指定容器化程序的程序 ID 或程序組 ID進行追蹤。OpenResty XRay 還可以自動檢測同一主機內部執行的部分容器中的應用程式。
下面的這張螢幕截圖展示了 OpenResty XRay 的 Web 控制檯自動檢測到的一個正執行在 Kubernetes 容器內部的 Perl 目標應用程式。
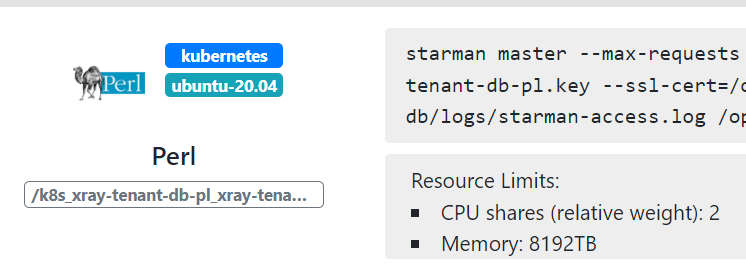
目標容器是不需要任何修改或者額外的許可權的。這也是 100% 非侵入式動態追蹤的美妙之處。
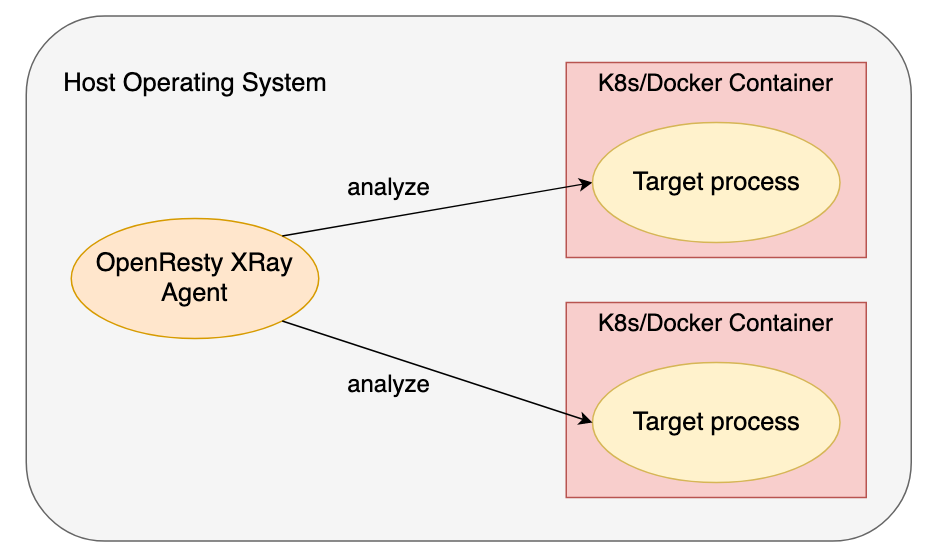
Y 語言 編譯器生成的工具由 OpenResty XRay 的 Agent 守護程序執行和管理。後者可以透明地檢視在同一主機作業系統中執行的任何 Docker 和 Kubernetes 容器,而無需目標容器本身的協作。
有些使用者更喜歡在容器內執行 OpenResty XRay 的 Agent 程序。我們也支援這種方式,不過 Agent 容器必須是擁有特權的,否則它將沒有許可權檢查其他容器(這也是特權容器的定義)。
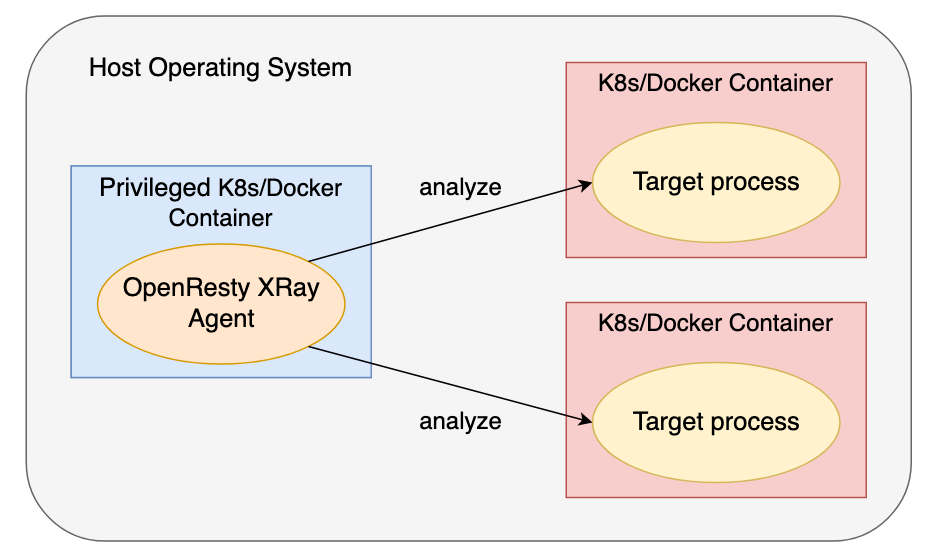
和往常一樣,OpenResty XRay 不會注入任何程式碼或要求在目標程序中進行任何更改。目標容器中原有的安全隔離和許可權不會受到任何損害。
高效的棧展開
Y 語言 編譯器可以自動將棧展開(由 OpenResty XRay 的包資料庫索引)編譯成非常高效的原生代碼,該程式碼執行時棧展開以生成執行時棧的呼叫棧軌跡或僅從當前執行時棧中讀取特定的區域性變數。
呼叫棧軌跡是至關重要的,因為它們為當前的程式碼執行上下文或”程式碼路徑”提供了一種自然的呈現方式。它們是許多分析器的基石,其中包括為 CPU、延遲和記憶體使用情況的分析生成的火焰圖。
以下是一個簡單的 Y 語言 示例:
_probe usleep() {
_print(_sym_ubt(_ubt()));
}
在 C 函式 usleep 的入口點上放置一個動態探針,並列印出一個簡易的 C 呼叫棧軌跡字串。典型輸出如下:
f95e0: usleep[1]
401134: main[0]
27082: __libc_start_main[1]
40106e: _start[0]
請注意,方括號([])中的整數數字表示目標程式模組檔案的索引。0 表示主要的可執行檔案,稱為 a.out,而 1 則表示 a.out 所依賴的 libc-2.27.so 檔案。使用者可以在 OpenResty XRay 中快速獲取實際的對映關係。
完整的 C 函式呼叫棧軌跡
Y 語言 的一些後端還支援內建函式 _print_full_ubt() 應用於所有的棧上的函式幀中,以引數和本地變數值的形式輸出完整的呼叫棧軌跡。以下是一個示例:
_probe usleep() {
_print_full_ubt();
}
當使用 ODB 後端時,輸出可能如下所示:
f95e0: usleep[1] (useconds=0x3)
ts=0x0
401134: main[0]
27082: __libc_start_main[1] (main=0x401126, argc=1, argv=0x7ffcd83d8378, init=<optimized>, fini=<optimized>, rtld_fini=<optimized>, stack_end=0x7ffcd83d8368)
result = <optimized>
unwind_buf=0x0
not_first_call = <optimized>
afct = <optimized>
head = <optimized>
cnt = <optimized>
__value = <optimized>
__value = <optimized>
ptr = <optimized>
__p = <optimized>
__result = <optimized>
40106e: _start[0]
這看起來與 GDB 的 bt full 命令的輸出非常相似。
從 C 執行時棧讀取特定變數值
完整的呼叫棧軌跡輸出可能非常昂貴。有時,我們只需要從當前執行時棧中讀取特定變數,這就會變得非常高效了。例如,如果我們使用 Y 語言 函式 _stack_var("r", 1) ,它將返回當前執行時棧(從時棧頂部到底部)名為 r 的第一個非最佳化本地變數的值(包括函式引數)。這個函式 _stack_var 目前還不在 OpenResty XRay 產品中提供,但它已經存在於我們的內部程式碼儲存庫中。一旦釋出,我們將及時更新本文。
動態語言呼叫棧軌跡
Y 語言透過標頭檔案提供標準庫,用於生成動態語言的呼叫棧軌跡。動態語言包括 Lua、PHP、Python 和 Perl 等指令碼語言。一些高階靜態型別語言,比如 Go (golang)、Rust 和 C++ 也是支援的。未來還將支援更多語言,例如 Ruby、Java(JVM)、JavaScript(NodeJS)、OCamel、Haskell 和 Erlang 等等。
接下來,我們將說明如何列印 Lua 和 PHP 語言的呼叫棧軌跡。
Lua 呼叫棧軌跡
例如,當某些 Lua 程式碼在 LuaJIT 2.1上執行時,我們可以編寫以下程式碼生成 Lua 級別的呼叫棧軌跡字串:
#include "lj21.y"
_probe lj_cf_os_exit() {
printf("%s", lj_dump_bt(NULL, "min"));
}
在這裡,我們把一個動態探針放在 C 函式 lj_cf_os_exit() 的入口點上,然後以最小化格式輸出 Lua 級別的呼叫棧軌跡。這是一個示例輸出:
$ run-y -c 'luajit test.lua'
test.lua:c
test.lua:b
test.lua:a
test.lua:0
C:pmain
test.lua 檔案如下所示:
local function c()
local baz = "hello"
os.exit(0)
end
local function b()
local bar = 3.14
c()
end
local function a()
local foo = 32
b()
end
a()
Lua 函式 os.exit() 將觸發 LuaJIT 虛擬機器內部的 C 函式 lj_cf_os_exit() 。
由 OpenResty XRay 提供的 Lua 級別火焰圖分析器使用類似的 Y 語言程式碼來生成火焰圖。這是一個示例圖表:
完整的 Lua 呼叫棧軌跡
我們可以透過上述提到的 Y 語言 程式中編寫 lj_dump_bt(NULL, "full") 來獲取完整的 Lua 呼叫棧軌跡,這其中包含每個 Lua 函式棧幀中本地 Lua 的變數值。針對上面示例的指令碼 test.lua ,以下是一個示例輸出:
[builtin#os.exit]
exit
test.lua:3
baz = "hello"
test.lua:c
test.lua:8
bar = 3.140000
test.lua:b
test.lua:13
foo = 32
test.lua:a
test.lua:16
c = function @test.lua:1: (GCfunc *)0x7feff0851578
b = function @test.lua:6: (GCfunc *)0x7feff0851658
a = function @test.lua:11: (GCfunc *)0x7feff08516c8
C:pmain
即使 Lua 標準庫在預設情況下也不支援完整的呼叫棧軌跡。Y 語言 也無需 LuaJIT 虛擬機器或目標程序配合與協議,因為它瞭解 LuaJIT 虛擬機器的內部。
PHP 呼叫棧軌跡
以下是一個用於轉存 PHP 7 的呼叫棧軌跡示例:
#include "php7.y"
_probe _timer.profile {
printf("%s\n", php7_dump_bt());
_exit();
}
這是一個示例輸出:
C:sapi_cli_single_write
Application->setLogger
/tmp/test.php:24
C:sapi_cli_single_write
Application->getLogger
/tmp/test.php:30
C:sapi_cli_single_write
class@anonymous@/tmp/test.php:24$0->log
/tmp/test.php:30
與開源工具鏈的比較
SystemTap 直接將棧展開(通常以 DWARF 格式)嵌入到其編譯後的工具中,並在執行時解析棧展開。這種方式速度很慢,是因為棧展開格式(例如 DWARF )是一種複雜的資料格式1,而且通常是為了緊湊性和空間利用率來最佳化,並不是為了速度。 Y 語言 是一個真正的編譯器,它將 DWARF 資料轉換為專用的原生代碼並且以儘可能快的速度執行。 GDB 也同樣解析 DWARF 資料,而不是作為一個實際的編譯器工作。
Linux 的 perf 將完整的執行時棧記憶體內容複製到使用者態以進行棧展開,但這種方式有以下缺點:
它可能會從核心空間複製過多的資料到使用者態,並且大部分資料對於執行時的棧展開都是無用的。這種複製操作可能會很快跑滿記憶體匯流排,並暴露敏感資料,易受安全漏洞的威脅。
複雜的工具無法直接在核心空間中利用呼叫棧軌跡。
而開源的 eBPF 工具鏈依賴於要在目標程式中使用的幀指標暫存器2,這與 x86_64 的 ABI 規範相違背。使用者也不得不使用 C/C++ 編譯器標誌 -fno-omit-frame-pointer 重新編譯大多數目標程式,這就又違反了動態追蹤的黃金法則:不需要目標程式禁用最佳化,也不需要目標程式專門配合。
開源工具鏈均不支援棧展開動態語言的函式來呼叫執行時棧或者是生成它們的呼叫棧軌跡。
分析已終止程序( Core Dumps 檔案 )
Y 語言的 GDB 後端對於分析已崩潰的程序生成的 core dump 檔案是非常有用的。至於其他後端,如 Stap+ 和 eBPF ,均不支援 core dump 檔案。
這是第一次,相同的分析工具可以分析活動程序和已終止的程序。這要歸功於高階語言 Y 語言 ,相同的分析工具首次可以同時分析活動程序和死亡程序。
當 Y 語言 用於 core dumps 的分析器中,除了 _oneshot 和 _begin 之外,指定任何其他探針幾乎沒有意義。畢竟,core dump 是已終止程序的“殘骸”3。
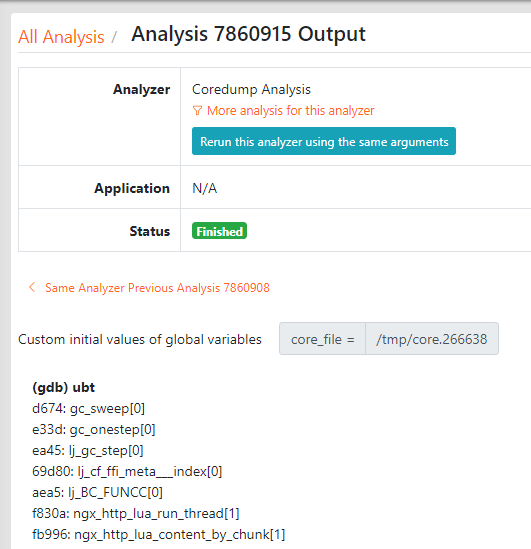
我們還計劃新增一個新的 Y 語言 後端,以支援 Red Hat 的 crash 命令列實用程式,這樣我們就可以使用 Y 語言 來除錯 Linux 核心的崩潰轉存檔案(例如來自 kdump 的檔案)。如此一看,分析作業系統核心的"殘骸"也是一個有趣的步驟。
極低的追蹤開銷
動態追蹤具有極低的執行時開銷,因為它只收集特定分析目標所需的資訊。這與傳統方法在日誌資料中收集儘可能多的資訊4的方式截然不同。後者是由於寫入和傳輸大資料而產生更高的開銷 5。
通常來講,動態追蹤也基於取樣的方式。因為它從不注入任何程式碼或載入特殊模組到目標程序中,所以當不進行取樣時,它的開銷嚴格為零。大多數分析工具的開銷通常是不可測量的,即使在取樣視窗期間也是如此。當目標應用程式達到最大吞吐量時,取樣成本通常低於吞吐量的 5%。一些全量檢測工具可能會產生更高的開銷,比如超過最大應用程式吞吐量的 30% 以上。然而,當線上效能已經降至極低水平時,我們也仍然可以在生產環境中使用它們。
Y 語言還是一個最佳化編譯器,可以為不同的後端生成緊湊且高效的程式碼。例如,由 Y 語言 的 GDB 後端生成的 Python 程式碼以接近四倍的速度快於手工編寫的程式碼6。
標準的 Y 語言庫和工具
正如我們在前面的部分中所看到的,Y 語言 提供了標準的標頭檔案來應用於匯入更多函式和其他功能,類似於 C/C++ 的中的程式碼重用方式。我們已經看到了像 lj21.y 和 php7.y 這樣的標準標頭檔案,它們構成了 Y 語言 的標準庫。我們同樣會使用 Y 語言 來實現這些標準庫。
未來,我們將會 Y 語言7中支援使用多個編譯單元以減少編譯器必須重新編譯的程式碼量。
另外,OpenResty XRay 提供了許多不同型別的開源軟體的標準分析器或工具,其中大多數工具都是用 Y 語言 編寫的。有些甚至是用如 YLua 和 YSQL 等更高階的語言編寫的。我們擁有可以在 Y 語言 之上構建語言抽象形式的整條“食物鏈”。例如,使用 Lua 語法來操作 Lua 級別的資料結構比使用 C 語法來檢查 C 級別的資料結構更加自然。
網路過濾和控制
您也可以使用 Y 語言 編寫在核心中執行的網路程式,以操控和處理網路資料包。這要歸功於 Linux 核心網路協議棧中的 eBPF 支援。eBPF 的前身 BPF 專門用於網路過濾。有了 Y 語言 和 OpenResty XRay 的 eBPF 工具鏈,我們不再受制於原始 eBPF 工具鏈和虛擬機器實現中的痛苦限制。我們有能力將強大的程式連線到 XDP 和 TC 子系統。
這個功能目前已經在 OpenResty XRay 中實現。並且 OpenResty DDoS 幻燈片也可以在我們 OpenResty Edge 的產品頁面中找到。
Y 語言編譯器的實現
Y 語言 編譯器是用 Fan 語言(或稱 fanlang)編寫的,Fan 語言是我們專門設計用於實現通用和特定領域語言的最佳化編譯器的 Perl 6(或 Raku)方言語言。Fanlang 編譯器生成了最佳化過的 LuaJIT 位元組碼,執行速度比 Rakudo8等開源的 Perl 6 實現要快得多。Fanlang 編譯器也將很快成為我們的 OpenResty Edge 和 OpenResty Plus 產品的一部分。
作業系統支援
Y 語言和 OpenResty XRay 支援大多數仍在維護生命期中的主流 Linux 發行版。而一些已經達到生命期終點的發行版版本,比如 Ubuntu 14.04 和 CentOS 6,在某種程度上來說仍然是可用的。
下一個將得到支援的大型作業系統版本是 Android,因為它的核心本質上就是基於 Linux 的。Y 語言 的 eBPF+ 後端也即將在該平臺上直接執行。
我們還計劃支援更多不太常見的作業系統,如 *BSD 和 macOS。Windows 從技術上講也是有可能實現的。請繼續關注我們的最新動態!
對開源社群的貢獻
我們建立了 Y 語言 和 OpenResty XRay 來幫助排查和最佳化各種開源軟體。如今,開源軟體無處不在,但很少有人對自己日常使用和喜愛的開源軟體有真正深入的瞭解。甚至許多人可能沒有正確地利用這些開源軟體,或者使用方式不夠最佳化。Y 語言 和 OpenResty XRay 本身也利用了大量高質量的開原始碼。
Y 語言使得建立極其複雜的分析器和工具變得輕而易舉,這對底層的開源基礎設施帶來了前所未有的壓力。事實上,我們在幾乎所有使用的開源元件中都遇到了許多難以理解的問題,比如 SystemTap、Clang/LLVM、libbpf、GDB 和 Linux 核心(包括 eBPF 機制、perf 事件、libbpf、btftool等)。
我們一直在積極向這些開源專案彙報問題並提交修復補丁,以幫助改進和最佳化開源社群。在這裡特別感謝 SystemTap 專案的作者 Frank Ch. Eigler,他迅速審查並接受了我們的補丁,並在多年來一直給予了我們大力支援。我們也一直主導著我們的開源專案,比如 OpenResty,並且對開源運動的價值抱有巨大的信心。
結論
Y 語言是一個通用的除錯和動態追蹤語言,針對許多不同的除錯框架和執行時環境。此外,Y 語言 使用的後端還解決了許多開源對應產品(如果有對應產品)的限制,也同時新增了許多新功能。現在開發新的動態追蹤工具變得更加容易了。使用者可以透過 OpenResty XRay 產品使用 Y 語言 和工具鏈,或者使用我們編寫的 Y 語言 標準分析器。
本系列文章以簡單的示例為您介紹了 Y 語言 的特點和優勢的高層次概述,並提供了簡單的示例。您可以在官方文件中找到有關 Y 語言 的更多詳細資訊。
致謝
我們的工作是站在許多動態追蹤和除錯領域的巨人肩膀上的。
Brendan Gregg 的部落格在 2012 年首次引起了我的興趣,當時他主要談論 DTrace。近年來,他在 Linux 的 eBPF 和 perf 工具鏈領域的工作仍然激勵著我們。
2012 年至 2016 年期間,我在 Cloudflare 工作時,Cloudflare 為我們提供了一個巨大的實驗場,以應用動態追蹤技術來解決大規模雲環境中的實際問題。
Frank Ch. Eigler 的 SystemTap 提供了最強大的開源動態追蹤框架,在早期給我提供了很大的幫助。多年來,我們也一直與 Frank 和其他 Red Hat 的 SystemTap 開發工程師們密切合作。
致力於 Linux 的 eBPF 工作的人們同樣值得敬佩。他們將 DTrace 的核心虛擬機器的強大功能引入 Linux 核心,並將其擴充套件到網路和跟蹤領域。
特別感謝我們的 OpenResty Inc. 開發工程師們,使 Y 語言 和 OpenResty XRay 成為現實。同時,還要感謝所有我們的 OpenResty XRay 使用者,每天都在幫助改進產品。
最後,我也同樣要感謝的是,21 世紀初在 Sun Microsystems 建立 DTrace 的開發工程師們。他們的這一創新掀開了計算機世界的嶄新篇章。
關於作者
章亦春是開源 OpenResty® 專案創始人兼 OpenResty Inc. 公司 CEO 和創始人。
章亦春(Github ID: agentzh),生於中國江蘇,現定居美國灣區。他是中國早期開源技術和文化的倡導者和領軍人物,曾供職於多家國際知名的高科技企業,如 Cloudflare、雅虎、阿里巴巴, 是 “邊緣計算“、”動態追蹤 “和 “機器程式設計 “的先驅,擁有超過 22 年的程式設計及 16 年的開源經驗。作為擁有超過 4000 萬全球域名使用者的開源專案的領導者。他基於其 OpenResty® 開源專案打造的高科技企業 OpenResty Inc. 位於美國矽谷中心。其主打的兩個產品 OpenResty XRay(利用動態追蹤技術的非侵入式的故障剖析和排除工具)和 OpenResty Edge(最適合微服務和分散式流量的全能型閘道器軟體),廣受全球眾多上市及大型企業青睞。在 OpenResty 以外,章亦春為多個開源專案貢獻了累計超過百萬行程式碼,其中包括,Linux 核心、Nginx、LuaJIT、GDB、SystemTap、LLVM、Perl 等,並編寫過 60 多個開源軟體庫。
關注我們
如果您喜歡本文,歡迎關注我們 OpenResty Inc. 公司的部落格網站 。也歡迎掃碼關注我們的微信公眾號:

翻譯
我們提供了英文版原文和中譯版(本文)。我們也歡迎讀者提供其他語言的翻譯版本,只要是全文翻譯不帶省略,我們都將會考慮採用,非常感謝!
例如,在 x86_64 架構上,幀指標暫存器是
rbp。 ↩︎我們擁有專有技術,可以透過將 core dump 檔案載入到復活的程序中,使已崩潰的程序復活。您可以自由使用 Y 語言 中的所有探針,如函式探針和系統呼叫探針來進行追蹤。 ↩︎
日誌資料可以儲存在檔案系統上,也可以實時傳送到網路上。 ↩︎
這需要大量的 CPU 時間、記憶體頻寬、磁碟/網路頻寬等等。 ↩︎
由 Y 語言 編譯器生成的 GDB Python 程式碼不使用 ``gdb.Value
或gdb.Type` 物件,這非常明顯地減少了執行時開銷。人類無法編寫這樣的 Python 程式碼,因為這對於生物大腦來說太複雜了。 ↩︎它也類似於 C 和 C++ 語言。 ↩︎
相關文章
OpenResty XRay Aug 22, 2023

OpenResty XRay Aug 21, 2023

OpenResty XRay Jul 6, 2023

OpenResty XRay Nov 24, 2023
")
OpenResty XRay Aug 6, 2023
")

















")
")
{kind=link}