Ylang: 適用於 eBPF、Stap+、GDB 等框架的通用語言(第三集,全四集)
本文是系列文章“Ylang:適用於 eBPF、Stap+、GDB 等的通用語言”的第三集。還可以參閱第一集、第二集和第四集。
Y 語言的語法(接上文)
字串
Ylang 支援 C 語言的字串字面量語法,即雙引號括起來的字串。
但是需注意每個 Ylang 程式中的兩個記憶體空間。預設情況下,字串字面量作為 Ylang 內建字串存在於跟蹤器空間中。而當我們嘗試獲取這些字串字面量的地址時,Ylang 將自動在追蹤物件的記憶體空間(即目標程序)中找到確切的字面量字串,並返回一個在追蹤物件空間中的地址。例如:
const char *s = "hello, world\n";
在後臺,Ylang 會盡力掃描目標程序的 .rodata 節,並返回匹配字串的虛擬記憶體地址(只有第一個匹配項有效)。如果沒有匹配項,Ylang 編譯器將出現編譯時錯誤。通常 .rodata 節的資料由 OpenResty XRay 的資料庫包索引,這樣 Ylang 編譯器就不需要自己每次分析目標可執行檔案了。
內建的正規表示式支援
在 Ylang 中,支援原生的 Perl 相容正規表示式(或 regexes)。許多 Perl 正規表示式語法的標準特性都得到支援。Ylang 使用 OpenResty 正規表示式最佳化編譯器為使用者的正規表示式生成高效的程式碼。我們專有的自動機演算法保證了與輸入字串長度成線性匹配時間,並且無論輸入字串的內容和大小,記憶體使用量始終保持恆定。
下面是一個示例:
_probe _oneshot {
_str a = "hello, world";
if (a !~~ rx/^([a-z]+), ([a-z]+)$/) {
_error("not matched");
}
_print("0: ", $0, ", 1: ", $1, ", 2: ", $2, "\n");
}
執行這個 Ylang 程式時,我們會得到以下輸出:
$ run-y test.y
Start tracing...
0: hello, world, 1: hello, 2: world
我們使用特殊變數 $0 來捕獲與整個正規表示式匹配的子字串,$1 、$2 用於捕獲子匹配組。
OpenResty 正規表示式編譯器可以構建一個最小的確定有限自動機(DFA),其形式如下:
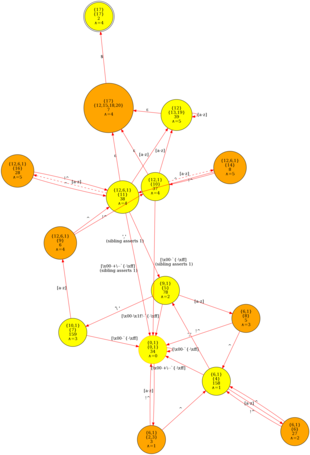
完整控制流支援
Ylang 支援所有的 C 控制流語句,如 for、while、do while、if、else、switch/case、break、continue 等。甚至 C 的 goto 語句在 Ylang 的所有後端(Stap+、eBPF、ODB 和 GDB)中都可以執行。除此之外還支援遞迴函式呼叫。下面是一個來自 LuaJIT 原始碼樹的 C 程式碼片段,也是一個有效的 Ylang 程式碼。
restart:
lname = debug_varname(pt, proto_bcpos(pt, ip), slot);
if (lname != NULL) { @name[0] = lname; return "local"; }
while (--ip > proto_bc(pt)) {
BCIns ins = *ip;
BCOp op = bc_op(ins);
BCReg ra = bc_a(ins);
if (bcmode_a(op) == BCMbase) {
if (slot >= ra && (op != BC_KNIL || slot <= bc_d(ins)))
return NULL;
} else if (bcmode_a(op) == BCMdst && ra == slot) {
switch (bc_op(ins)) {
case BC_MOV:
if (ra == slot) { slot = bc_d(ins); goto restart; }
break;
default:
return NULL;
}
}
Ylang 中的所有迴圈都是有限的,包括通用的 goto 語句。每個探測處理程式只允許執行有限數量的 Ylang 語句,不過這個限制是可配置的。此外,使用者可調的閾值限制了遞迴函式呼叫深度。Ylang 編譯器確保 Ylang 程式能快速終止,並使用有限的堆疊大小。實質上,我們擁有一個非常高效的執行時沙盒,用於 Y 編譯器生成的工具。
值得注意的是,eBPF 具有最小的迴圈結構,其中迴圈必須在編譯時展開。開源的 eBPF C 語言禁止一般的迴圈,特別是後向跳轉。這不僅使目標應用程式中程式碼重用變得非常困難,而且重寫經過驗證的重要 C 程式碼控制流還非常容易出錯。在 動態追蹤 工具本身排除程式故障是很有挑戰性的,標準的 eBPF 驗證器在預估執行的 eBPF 指令總數方面也表現不佳。例如,一個大的 switch 語句可能會超過其 100 萬條指令的限制,儘管實際上只有幾條指令用於單個 case 語句的執行。OpenResty XRay 的 eBPF 實現沒有這些限制,而且即使 Ylang 程式本身有錯誤,也仍能確保所有的 Ylang 程式在生產系統中始終安全執行。
DTrace 的 D 語言沒有任何迴圈結構,DTrace 使用者必須自己展開迴圈。
儘管開源的 SystemTap 具有非常靈活的控制流語句,但它仍然缺少 goto 語句。而 OpenResty XRay 的 Stap+ 工具鏈就沒有這種限制。
浮點數支援
Ylang 的所有後端都支援浮點數。float 和 double 這兩種 C 資料型別在追蹤者空間和被追蹤者空間都可以使用。
下面是一個用於在追蹤者空間進行浮點數運算的示例:
double a = 3.1234512345123451234;
double b = 1.8123451234512345123;
_probe _oneshot(void) {
printf("a + b: %.15f\n", a + b);
printf("b + a: %.15f\n", b + a);
printf("a - b: %.15f\n", a - b);
printf("b - a: %.15f\n", b - a);
}
我們用 run-y 工具來執行它:
$ run-y test.y
Start tracing...
a + b: 4.935796357963580
b + a: 4.935796357963580
a - b: 1.311106111061111
b - a: -1.311106111061111
對於被追蹤者空間,我們也可以從目標程序的記憶體中讀取浮點數。假設目標 C 程式有一個如下所示的結構型別的變數:
typedef struct foo {
double d;
float f;
} foo;
foo obj = { 3.14, -0.01 };
int main(void) {
return 0;
}
它既有 double 型別的欄位,也有一個 float 型別的欄位。我們用以下的 Ylang 程式碼片段來讀取這些欄位:
_target static foo obj;
_probe main() {
printf(".d: %f\n", obj.d);
printf(".f: %f\n", obj.f);
}
這個 Ylang 程式的輸出如下:
$ run-y -c ./a.out test.y
Start tracing...
.d: 3.140000
.f: -0.010000
這裡的 ./a.out 是從上面的目標 C 程式碼編譯出來的可執行檔案。
與開源工具鏈的比較
大多數基於核心的開源工具鏈都不支援浮點數,除了 Solaris 上的 DTrace 和 SystemTap 是。而 SystemTap 中的浮點數語法也非常繁瑣,用 tapset 函式來處理涉及浮點數的所有內容(如 fp_lt、fp_to_long 和 fp_add)特別麻煩。
清晰的除錯符號方式
現代最佳化編譯器可以生成除錯符號(或除錯資訊),讓在不犧牲執行時效能的情況下除錯二進位制程式成為可能。它本質是偵錯程式在冷冰的二進位制世界中的導航地圖。這些除錯符號讓我們可以在 Ylang 程式中直接透過名稱引用任何資料型別、欄位名、函式和全域性/靜態變數。Ylang 將這些名稱對映到為 Stap+、eBPF、GDB 等生成的分析器中的數字。1
除錯符號:無執行期系統開銷
C/C++ 編譯器通常支援 -g(或類似的選項,如 -g3 和 -ggdb),它會在特殊的 ELF 檔案節(如 .debug_info 和 .debug_line)中生成除錯符號。除錯符號可能以 DWARF 格式儲存。有時編譯器可能會使用其他除錯資料格式,如 CTF 和 BTF。當作業系統載入可執行檔案時,這些除錯符號不會對映到記憶體中,因此不會產生執行時開銷。這些除錯節還可以被剝離成單獨的除錯檔案,並且在生產系統中可能不存在。例如,基於RPM的系統通常將獨立的除錯符號收集到專用的 *-debuginfo RPM 軟體包中,而基於 APT 的系統則提供專用的 *-dbgsym 或 *-dbg DEB 軟體包。
集中的軟體包資料庫
我們的爬蟲不斷從主流 Linux 發行版中獲取所有的公共二進位制軟體包,比如 Ubuntu、Debian、CentOS、Rocky、RHEL、Fedora、Oracle、OpenSUSE、Amazon、Alpine 等,以及許多熱門開源軟體的軟體包倉庫(如 MySQL 和 PHP),並補充給 OpenResty XRay 的軟體包資料庫。此外,如果使用者的系統具有帶有嵌入或單獨除錯符號的自定義可執行二進位制檔案,OpenResty XRay 將自動收集除錯符號。然後,它在軟體包資料庫的特定於租戶的資料庫中索引這些資料。出於安全和隱私考慮,不同的租戶無法看到其他人的私有除錯符號。由於集中的軟體包資料庫不斷增長,使用者不需要在每臺擁有相同程式二進位制檔案的機器上安裝除錯符號。只需要為 OpenResty XRay 檢視特定可執行二進位制檔案的除錯符號一次即可。儘管當前系統中沒有可用的除錯符號,它也可以自動將相同的二進位制檔案對映到已經索引的正確版本的除錯符號。
軟體包資料庫還會處理除錯符號資料,併為 Ylang 編譯器構建高效的索引。處理複雜的除錯資料格式(如 DWARF)非常昂貴,因此最好只進行一次格式解析。它還會呼叫我們針對 Linux 核心的模糊測試(fuzz testing)系統,以確保新的核心軟體包(包括使用者的自定義核心)與我們的動態追蹤工具鏈沒有問題。
軟體包資料庫非常龐大!截至本文撰寫時,它已經佔用了數百 TB 的空間,並且在不斷增長。因此,OpenResty XRay 的本地版本仍然需要透過(加密的)網際網路連線訪問我們的集中只讀資料庫包以獲取公共軟體包。但是,對於本地版本,軟體包資料庫的租戶部分駐留在使用者的計算機上。
截至本文撰寫時,OpenResty XRay 僅支援 DWARF 格式。未來我們計劃將新增對 CTF 和 BTF 的支援。
模糊匹配除錯符號
有時人們為了減小記憶體,故意在構建或打包過程中剝離程式二進位制檔案,比如在編譯程式時不新增除錯符號2,或者找不到除錯符號包3。在這種情況下,我們仍然可以透過模糊匹配現有的除錯符號在 OpenResty XRay 中自動構建大部分除錯符號,用於類似但不完全相同的可執行二進位制檔案。這需要先進的機器學習和逆向工程技術。儘管還沒有在 OpenResty XRay 中應用,但我們已經在這方面做了很多工作。對於使用者的自定義程式,在開源世界中沒有“相似”的二進位制檔案的情況下,唯一的方法是使用 -g 編譯器選項重新編譯這些二進位制檔案,使其可除錯。
未完待續
以上就是我想在第三集中介紹的內容,我會在第四集繼續介紹 Ylang 的更多功能和優點。
關於作者
章亦春是開源 OpenResty® 專案創始人兼 OpenResty Inc. 公司 CEO 和創始人。
章亦春(Github ID: agentzh),生於中國江蘇,現定居美國灣區。他是中國早期開源技術和文化的倡導者和領軍人物,曾供職於多家國際知名的高科技企業,如 Cloudflare、雅虎、阿里巴巴,是“邊緣計算”、“動態追蹤”和“機器程式設計”的先驅,擁有超過 22 年的程式設計及 16 年的開源經驗。作為擁有超過 4000 萬全球域名使用者的開源專案的領導者。他基於其 OpenResty® 開源專案打造的高科技企業 OpenResty Inc. 位於美國矽谷中心。其主打的兩個產品 OpenResty XRay(利用動態追蹤技術的非侵入式的故障剖析和排除工具)和 OpenResty Edge(最適合微服務和分散式流量的全能型閘道器軟體),廣受全球眾多上市及大型企業青睞。在 OpenResty 以外,章亦春為多個開源專案貢獻了累計超過百萬行程式碼,其中包括,Linux 核心、Nginx、LuaJIT、GDB、SystemTap、LLVM、Perl 等,並編寫過 60 多個開源軟體庫。
關注我們
如果您喜歡本文,歡迎關注我們 OpenResty Inc. 公司的部落格網站 。也歡迎掃碼關注我們的微信公眾號:

翻譯
我們提供了英文版原文和中譯版(本文)。我們也歡迎讀者提供其他語言的翻譯版本,只要是全文翻譯不帶省略,我們都將會考慮採用,非常感謝!
相關文章
OpenResty XRay Sep 20, 2023

OpenResty XRay Aug 21, 2023

OpenResty XRay Jul 6, 2023

OpenResty XRay Nov 24, 2023
")
OpenResty XRay Aug 6, 2023
")

















")
")