Ylang: 適用於 eBPF、Stap+、GDB 等框架的通用語言(第一集,全四集)
這篇文章是“Y 語言:適用於 eBPF、Stap+、GDB 等的通用語言”系列的第一集。其他集詳見第二集,第三集和第四集。
Y 或 Ylang 是適用於多種動態追蹤框架和工具鏈的一種通用的動態追蹤語言。該語言是 OpenResty Inc. 開發的 OpenResty XRay 平臺的重要組成部分。
甚麼是動態追蹤
動態追蹤是一組技術的統稱。它可以對執行中的軟體系統進行分析並幫助軟體排除故障。這個過程是以安全、實時、事後、高效和非侵入的方式進行的。
許多類似於 APM 的技術都聲稱是非侵入性的,實際上它們仍然需要目標程序和應用程式的專門配合。例如,它們可能需要載入特殊的模組和庫,向目標程序注入新的程式碼,或者要求它們透過 API 呼叫或日誌檔案來輸出資料。
我曾經寫過一篇文章詳細介紹動態追蹤,標題是“動態追蹤技術漫談”。歡迎您去看看。
為甚麼命名為 “Y”
您可能想知道為甚麼我把這門語言起名為 Y。這是我還在 Cloudflare 工作的時候,公司的執行長 Matthew Prince 給起的名字。他說這是我名字的第一個字母,Yichun,更重要的是,它與 “為甚麼(why)” 這個詞同音。動態追蹤語言通常旨在回答以“為甚麼”開頭的複雜問題。那個時候,Ylang 還是一個非常模糊的想法。幾年之後成立 OpenResty 公司的時候我選擇了保留這個名字,感謝 Matthew。
入門
Hello World 的例子
讓我們用 Y 語言實現一個經典的 “hello world” 的例子:
$ run-y -e '_probe _oneshot { printf("Hello, world!\n"); }'
Start tracing...
Hello, world!
run-y 工具來自於 OpenResty XRay 包。
這裡的 _probe 關鍵字為特殊探測點 _oneshot 定義了一個新的探針處理程式,在分析器啟動的時候被觸發。而當 _oneshot 探針執行完畢後,分析器會立即退出。printf() 函式的作用等同於標準 C 語言的 printf() 函式。
指定目標程序
使用特殊的 _oneshot 探針是嘗試 Y 語言特性的一個好方法。我們將在本系列文章的後面看到更多的例子。一般來說我們會使用其他種類的探針來進行真實的分析,如函式探針、系統呼叫探針、程序排程器探針、CPU 分析器探針等等。在這些情況下,我們可以透過 PID 指定一個執行中的目標程序,如
# 假設目標程序的 PID 為 5786
run-y -p 5786 my-tool.y
也可以指定一個程序組 ID(PGID),如
# 假設目標程序組有相同的程序組 ID,14927
run-y -p -14927 my-tool.y
如果一個實時程序的 PID 等於指定的程序組 ID,我們的工具鏈將自動從該程序中獲得真正的程序組 ID。指定 Nginx 主程序來跟蹤整個 Nginx 程序組是很方便的,其中主程序的 PID 與程序組 ID 並不 相同(當啟用守護程序模式的時候)。
如果我們想從程式啟動的時候就開始追蹤它的整個生命週期,我們應該在用 run-y 工具啟動程序的時候使用 c 選項,例如
run-y -c '/usr/bin/perl -e1' my-tool.y
這裡我們追蹤的是 perl 命令的整個生命週期。這可以確保我們不會錯過早期的探針,比如在 main 函式入口處的探針。
當沒有指定 -p 和 -c 選項時,run-y 工具預設會追蹤整個作業系統。
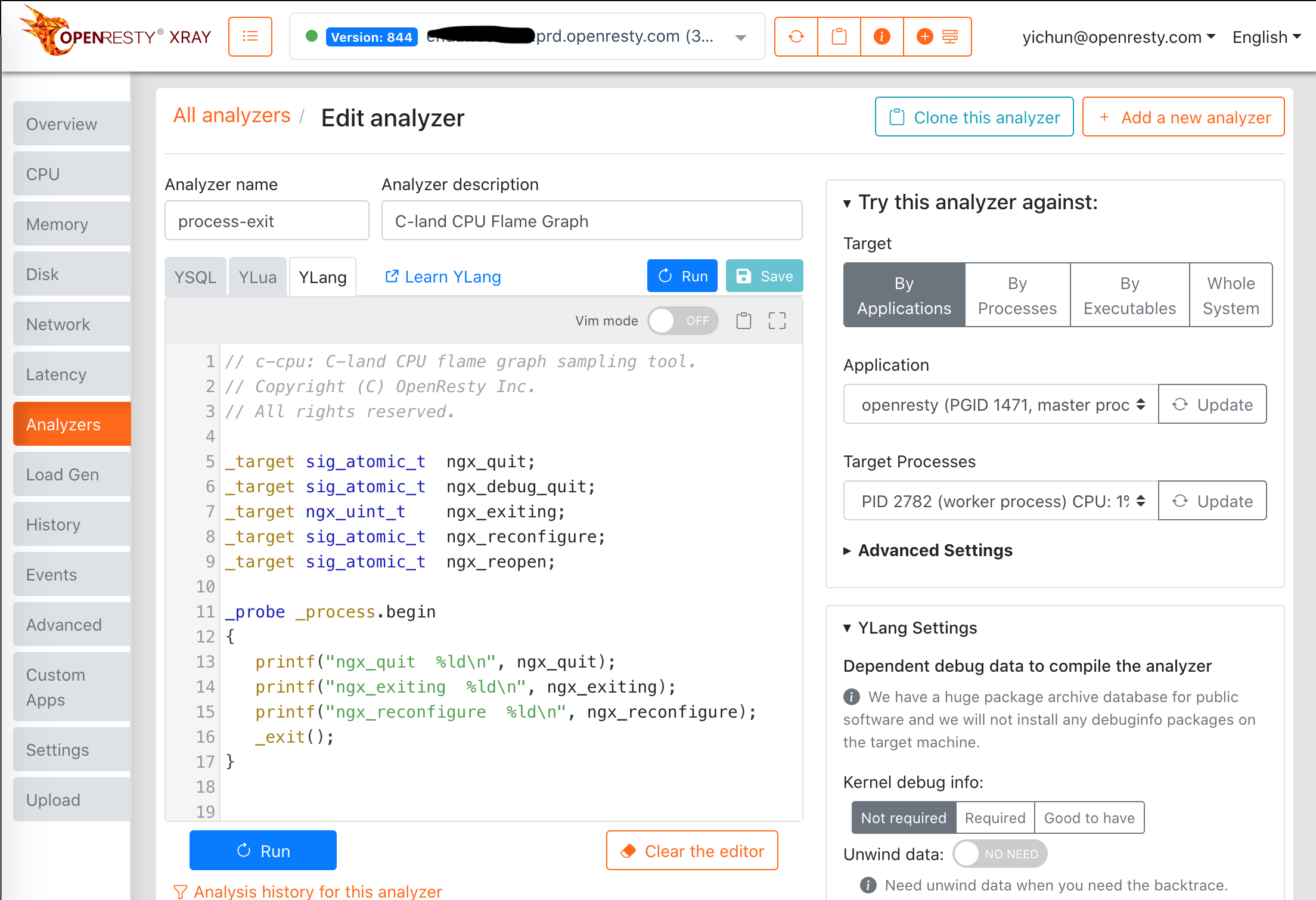
Web 控制檯
也可以使用 OpenResty XRay 的 Web 控制檯來編輯和執行 Ylang 程式或分析器。下方是該控制檯的截圖。
各種後端和執行時
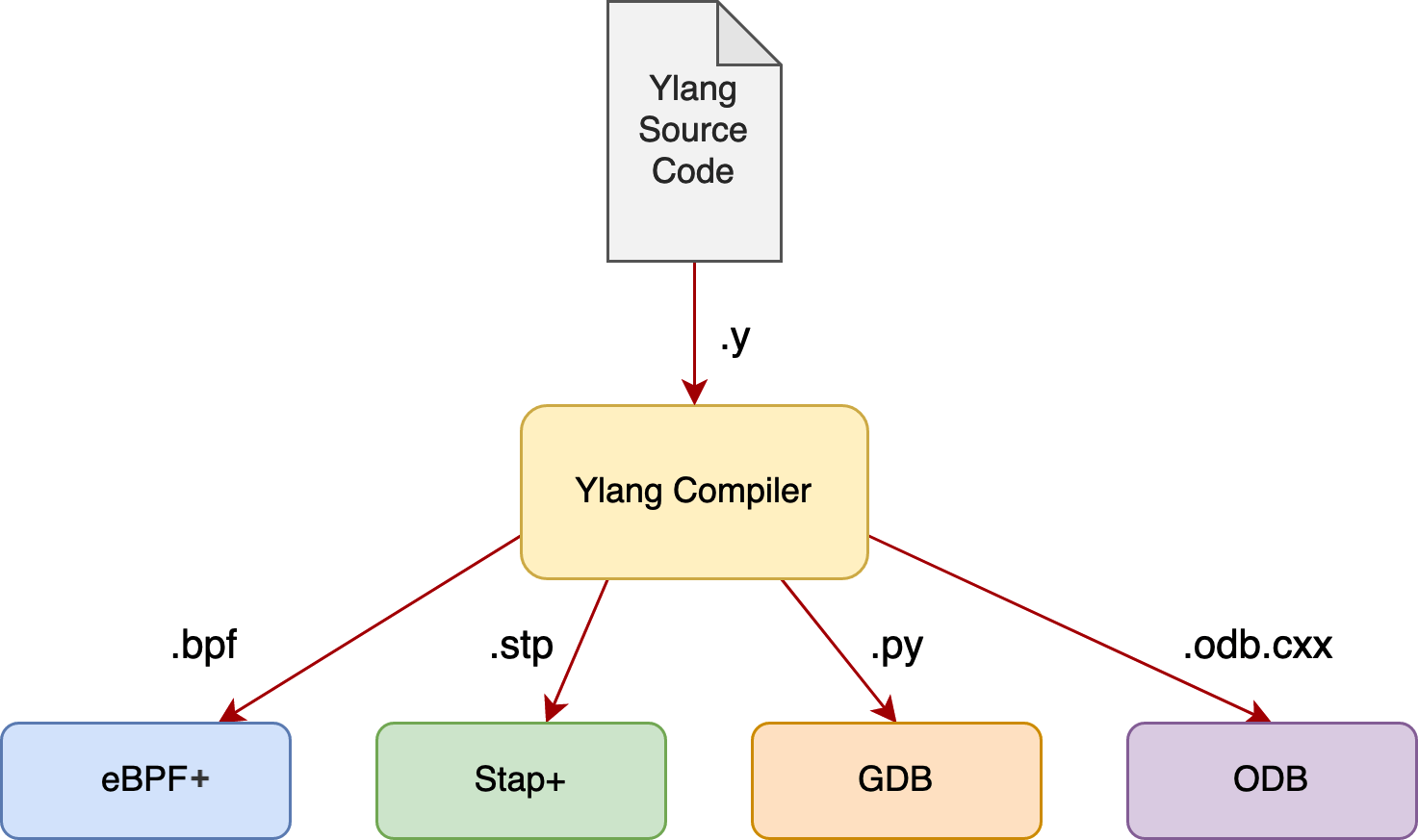
目前支援以下後端:
eBPF+(我們對 Linux 的開源 eBPF 虛擬機器和工具鏈進行了極大的改進)、
Stap+(我們對 Red Hat 公司的開源 SystemTap 進行了大量最佳化)、
GDB (GNU 專案偵錯程式)及其 Python 擴充套件,以及
ODB(OpenResty 偵錯程式,類似於 GDB,但要輕量很多)
為甚麼我們需要這麼多不同的除錯框架呢?這是因為每一種技術都有其優勢和劣勢,因此有各種不同的使用場景。現在讓我們逐個來分析它們:
eBPF 是一個相對較新的技術,所以它通常需要較新的 Linux 核心。但是它編譯和載入工具的速度比諸如 SystemTap(有著預設的核心執行時)這樣的框架要快得多。
Stap+ 與 SystemTap 類似。兩者都能在很多核心版本上工作,甚至是 CentOS 7 的 3.10 核心(但不要誤以為這裡指的是標準的 3.10 核心,Red Hat 已經從較新的核心上回傳了大量補丁)。
GDB 是唯一可以分析 core dump 檔案(來自崩潰的程序)的後端。但是,它仍然可以使用斷點來模擬函式探測和動態追蹤,只是速度很慢,成本很高。
ODB 與 GDB 相似,但沒有 GDB 那樣的歷史包袱。它仍然是一個純粹的 user-land 跟蹤框架,但比 GDB 快了好幾個數量級。對於一些有缺陷的 Intel Xeon CPU,它們可能會在完全有效的記憶體訪問請求中產生大量的頁面錯誤。在這種情況下,基於核心的動態追蹤,如 eBPF 和 Stap+ 往往不能在禁用頁面錯誤的情況下讀取目標程序的記憶體。因此 ODB 是這類晶片上的唯一選擇。
我們計劃支援更多的後端,比如 LLVM 的 LLDB(透過其 Python 擴充套件 API,就像 GDB)和用於分析崩潰的 Linux 核心的 core dump(kdump)檔案的工具。
通常情況下,OpenResty XRay 會自動選擇或重新選擇適合當前用例和環境的後端。但使用者也可以明確地選擇一個特定的執行時。
為甚麼要使用一個統一的前端語言
Ylang 是一個可以應用於所有除錯和動態追蹤框架的統一的前端語言。它可以避免我們為上述不同的應用場景編寫大量的重複程式碼。一個單一的 Ylang 工具可以立即在各種技術和框架中使用,實現線上跟蹤、core dump 檔案分析等多種目的。Ylang 編譯器可以確保在不同的後端中精確保留語義,從而節省大量的人力。
Y 語言的語法
Ylang 擴充套件了 C 語言的一個龐大的子集,為動態追蹤提供了語法和原語。C 程式設計師應該會覺得它非常容易使用。Ylang試圖能與 C 語言(甚至是 GNU C的一部分)在極細微的程度上達到真正地相容。事實上,我們可以把許多真實的 C 程式碼片段當作完全有效的 Ylang 程式碼,而無需進行任何編輯。畢竟,從 MySQL 和 PostgreSQL 這樣的資料庫到 CPython、Ruby、Perl 和 PHP 等高階語言直譯器和編譯器,許多開源程式和庫都是用 C 語言編寫的。甚至 Linux 核心也是用 C 語言編寫的。C++ 程式碼也可以透過 C++-to-C 編譯器轉換為 C 語言。因此,所有那些 C++ 開源專案,如 Chromium、Qt、JVM 和 NodeJS,也可以成為新的 Ylang 分析器和工具的程式碼來源。
為甚麼使用與目標軟體相同的語言如此重要呢?因為每次我們想為目標應用程式建立一個新的分析器時,編寫這種工具最繁瑣和費力的部分就是繞過目標的資料結構。目標應用程式本身又必須使用這些資料結構,所以最自然的方式是直接借用它們的那些成熟程式碼來收集我們需要的資訊。簡單的複製&貼上極大地降低了建立新的動態追蹤工具和分析器的成本。
除了 C 風格的 Ylang 之外,OpenResty XRay還提供了針對 Ylang 的其他語言的編譯器,如 Lua 語法的 YLua 和 SQL 語法的 YSql。我們將在後續的文章中介紹這些語言。我們也計劃支援更多的語言,比如 Python、Ruby、Java、Rust、Go 等語言的 Y 變種。
其他工具鏈使用的語言
Stap/D/Bpftrace: 與 C 類似但不是 C
其他開源框架,如 DTrace、SystemTap 和 Bpftrace(目標是 eBPF)都引入了自己的指令碼語言。不幸的是,這些語言只是看起來像 C 語言,而從來沒有想過要與 C 語言真正地相容。所以簡單地複製&貼上目標應用程式中的 C 程式碼是行不通的。要把程式碼移植到這些框架的指令碼語言上,是很費時費力的。如果工具的邏輯複雜,測試被移植工具的正確性和除錯其中的錯誤也很不容易。
對於真正的 C 程式設計師來說,它甚至可能看起來也不像 C。我們用 SystemTap 的指令碼語言舉個例子。看看下面的 Ylang 程式碼片段:
_target long *my_var;
int get_val(void) {
return *(int *) my_var;
}
除了特殊的 _target 關鍵字,這個片段看起來是完全就是 C 程式。_target 關鍵字是 Ylang 引入的一個擴充套件。這個關鍵字代表宣告的符號來自目標程序(或 tracee 空間)。如果我們想把這段程式碼變成 SystemTap 的指令碼,它將會是這樣的:
function get_val() {
return @cast(@var("my_var", "/path/to/target/exe/file"), "int", "/path/to/target/exe/file")[0];
}
這看起來很不一樣,更加冗長。我們必須在程式碼中硬編碼可執行檔案的路徑,或者透過宏來傳遞它。
這些指令碼語言最重要的痛點是缺少一個 C 風格的型別系統。通常只能用一個有符號的 long int 型別來表示整數。您必須自己模擬所有細微的 C 語言整數型別轉換和算術語義,這非常煩人,而且容易出錯。
您可以在 GitHub 的這些公共資源庫中檢視我們手寫的一些真實的複雜的 SystemTap 指令碼,openresty-systemtap-toolkit,以及 stapxx。這樣的指令碼語言通常用處不大,我們必須得寫一個 Perl wrapper 來把它們變成更有用的命令列工具。有些人喜歡用其他更強大的指令碼語言來寫這種 wrapper,比如 Python 和 Bash。
然而,透過 Ylang,使用者只需使用一種與 C 語言相容的語言,再也不需要其他指令碼語言的醜陋 wrapper 了。
eBPF: 是 C 但是比 C 更難
官方的 eBPF 工具鏈(包括 BCC)通常透過 LLVM 和 Clang 使用自然 C 語言。遺憾的是,這種 C 語言也有許多嚴重的限制,僅舉幾例:
- 使用者自定義的函式最多隻能接受 5 個引數1。
- 因為有 Linux 核心 eBPF 驗證器中的靜態程式碼分析器,流程控制語句有諸多限制。這個驗證器也為大型 eBPF 程式引入了很高的 CPU 開銷。向後跳轉和普通的迴圈通常是禁用的。
- 不允許透過函式返回值和引數傳遞複合型別的值(如 struct 和 union 值)2。
- 暫時還不支援跨
.data,.rodata,.bss和其他類似資料段的資料引用的重新定位3 。 - 沒有或很少有對目標程序中定義的型別的內建支援。所以使用者通常要自己手動宣告所有的型別。
- 沒有內建的 VMA 跟蹤器4支援,所以使用者必須自己計算虛擬記憶體地址,這非常繁瑣,而且容易出錯。
- 內建的 stack unwinder 從不使用目標程序的 unwinding tables 或 DWARF 資料,因此在編譯目標程序時會依賴於禁用幀指標暫存器。
- 除了 BPF Map 和基於堆疊的自動變數,執行時缺乏任何內建的記憶體分配和管理機制。即使是處理最普通的 C 字串,也是非常痛苦的。
- 在編譯器工具鏈和 BPF 指令集中都沒有帶符號的除法操作支援5。
- 不支援浮點數6。
我就說到這裡吧,類似的限制還有很多。我們經常這樣開玩笑,大多數人認為編寫核心 C 程式碼非常困難,實際上編寫稍微複雜一點的 eBPF C 程式碼比編寫核心 C 程式碼要難得多。幸運的是,Ylang 使用的 eBPF+ 實現幾乎解決了上面列出的所有問題,Ylang 編譯器可以為我們自動編寫這種複雜的 eBPF C 程式碼。我們可以寫出自然、乾淨的 C 語言程式碼,完全不用考慮那些煩人的細節。
儘管如此,標準的 eBPF 工具鏈還需要一個用像 Python 和 C 這樣的語言編寫的獨立的 user-land 程式(大多數人使用 Python)。這比用 SystemTap 的指令碼語言編寫的工具的 shell wrapper 更加麻煩。Ylang 編譯器也能自動生成這種 user-land 程式。(Ylang 可以為這類程式生成經過最佳化的 C 程式碼,因為 Python 既臃腫又緩慢)
GDB/LLDB: 根本不像 C
使用一種與 C 語言語法截然不同的語言來編寫分析 C/C++ 應用程式的工具只會更難。比如 GDB 和 LLDB,GDB 提供了 Python 和 Scheme 語言來編寫新的擴充套件。而 LLVM 提供了 Python。使用 Python 來跟蹤 Python 應用程式您可能感覺很自然,事實並非如此!這樣的 GDB Python 程式碼總是用來分析用低階語言如 C 寫的東西!這導致了即便是簡單的 C 邏輯,也會產生可怕的 Python 程式碼。例如,來看看下面這段簡單的 C 語句:
int a = *(int *) my_var;
其中 my_var 是目標程序中的一個變數。把它變成一個 GDB Python 程式碼段,是這樣的:
sym_my_var = gdb.lookup_global_symbol("my_var")
if sym_my_var is None:
sym_my_var, _ = gdb.lookup_symbol("my_var")
a = sym_my_var.value().cast(gdb.lookup_type("int").pointer()).dereference()
在 Ylang 中,您可以寫出前一種程式碼的格式,並像這樣宣告目標變數 my_var:
_target long *my_var;
注意 _target 關鍵字是 Ylang 的一個新擴充套件,表示目標軟體中的一個符號。
在 GDB Python 中,當複雜性積累到一定程度,情況很快會變得更糟。來看一個手寫的 GDB Python 指令碼中的一個糟糕的例子。這是最可怕的噩夢。
幸運的是,即使是 Ylang 編譯器也不必生成上述冗長且緩慢的 Python 程式碼。它可以繞過繁瑣的 gdb.Value 物件,生成更緊湊的程式碼,這有以下好處:
- 由此產生的 Python 程式碼在執行時明顯更快(有時會快幾倍)。
- 由此產生的程式碼也小得多,因為它更加緊湊。
- 由此產生的程式碼不再要求 DWARF 資料存在於目標環境中(因此,我們稱之為無 DWARF)。
儘管如此,Ylang 編譯器也可以生成這種慢速形式的程式碼,這種程式碼只有人類使用者才會使用,用來比較兩種不同的形式。
未完待續
這篇文章已經很長了。從第二集開始,我們將更加關注 Ylang 的特性和例子。
關於作者
章亦春是開源 OpenResty® 專案創始人兼 OpenResty Inc. 公司 CEO 和創始人。
章亦春(Github ID: agentzh),生於中國江蘇,現定居美國灣區。他是中國早期開源技術和文化的倡導者和領軍人物,曾供職於多家國際知名的高科技企業,如 Cloudflare、雅虎、阿里巴巴, 是 “邊緣計算“、”動態追蹤 “和 “機器程式設計 “的先驅,擁有超過 22 年的程式設計及 16 年的開源經驗。作為擁有超過 4000 萬全球域名使用者的開源專案的領導者。他基於其 OpenResty® 開源專案打造的高科技企業 OpenResty Inc. 位於美國矽谷中心。其主打的兩個產品 OpenResty XRay(利用動態追蹤技術的非侵入式的故障剖析和排除工具)和 OpenResty Edge(最適合微服務和分散式流量的全能型閘道器軟體),廣受全球眾多上市及大型企業青睞。在 OpenResty 以外,章亦春為多個開源專案貢獻了累計超過百萬行程式碼,其中包括,Linux 核心、Nginx、LuaJIT、GDB、SystemTap、LLVM、Perl 等,並編寫過 60 多個開源軟體庫。
關注我們
如果您喜歡本文,歡迎關注我們 OpenResty Inc. 公司的部落格網站 。也歡迎掃碼關注我們的微信公眾號:

翻譯
我們提供了英文版原文和中譯版(本文)。我們也歡迎讀者提供其他語言的翻譯版本,只要是全文翻譯不帶省略,我們都將會考慮採用,非常感謝!
這種錯過的重定位可能導致執行時出現 NULL 指標 deference,這可能導致 kernel panic。 ↩︎
eBPF C 開發人員應該熟悉 Clang 編譯器的錯誤 “不支援帶有 VarArgs 或 StructRet 的函式”。 ↩︎
VMA 跟蹤器將目標程序中的相對地址對映到絕對虛擬記憶體地址,反之亦然。 ↩︎
eBPF 的 C 語言開發人員應該對 Clang 編譯器的錯誤並不陌生,比如 “不支援 DAG 的帶符號的除法” 和 “後端錯誤:無法選擇:0x55ba75efac30: i64 = sdiv”。 ↩︎
許多動態追蹤框架不支援浮點數。唯一的例外是 SystemTap(它最近新增了這個功能)、GDB Python 和 Solaris 上的 DTrace(其他作業系統上的 DTrace 埠仍然缺乏這個功能)。 ↩︎
相關文章
OpenResty XRay Sep 20, 2023

OpenResty XRay Aug 22, 2023

OpenResty XRay Aug 21, 2023

OpenResty XRay Nov 24, 2023
")
OpenResty XRay Aug 6, 2023
")

















")
")