動態追蹤技術漫談
本文最初成稿於 2016 年 5 月初,後於 2020 年 2 月中進行了較大的更新和修訂,後續會持續保持更新。
甚麼是動態追蹤
我很高興能在這裡和大家分享動態追蹤技術(Dynamic Tracing)這個主題,對我個人來說也是一個很激動人心的話題。那麼,甚麼是動態追蹤技術呢?
動態追蹤技術其實是一種後現代的高階除錯技術。它可以幫助軟體工程師以非常低的成本,在非常短的時間內,回答一些很難的關於軟體系統方面的問題,從而更快速地排查和解決問題。它興起和繁榮的一個大背景是,我們正處在一個快速增長的網際網路時代,作為工程師,面臨著兩大方面的挑戰:一是規模,不管是使用者規模還是機房的規模、機器的數量都處於快速增長的時代。第二方面的挑戰就是複雜度。我們的業務邏輯越來越複雜,我們執行的軟體系統也變得越來越複雜,我們知道它會分成很多很多層次,包括作業系統核心然後上面是各種系統軟體,像資料庫和 Web 伺服器,再往上有指令碼語言或者其他高階語言的虛擬機器、直譯器及即時(JIT)編譯器,頂上則是應用層面的各種業務邏輯的抽象層次和很多複雜的程式碼邏輯。
這些巨大的挑戰帶來的最嚴重的後果就是,今天的軟體工程師正在迅速地喪失對整個生產系統的洞察力和掌控力。在如此複雜和龐大的系統中,各種問題發生的機率大大提高了。有的問題可能是致命的,比如 500 錯誤頁,還有記憶體洩漏,再比如說返回錯誤結果之類。而另一大類問題就是效能問題。我們可能會發現軟體在某些時候執行的非常緩慢,或者在某些機器上執行得非常緩慢,但我們並不知道為甚麼。現在大家都在擁抱雲端計算和大資料,這種大規模的生產環境中的詭異問題只會越來越多,很容易佔據工程師大部分的時間和精力。大部分問題其實是線上才有的問題,很難復現,或者幾乎無法復現。而有些問題出現的比率又很小,只有百分之一、千分之一,甚至更低。我們最好能夠不用摘機器下線,不用修改我們的程式碼或者配置,不用重啟服務,在系統還在執行的時候,就把問題分析出來,定位出來,進而採取有針對性的解決辦法。如果能做到這一點,那才是完美的,才能每晚都睡上一個好覺。
動態追蹤技術實際就能幫助我們實現這種願景,實現這種夢想,從而極大地解放我們工程師的生產力。我至今還記得當年在雅虎中國工作的時候,有時不得不半夜打車去公司處理線上問題。這顯然是非常無奈和挫敗的生活和工作方式。後來我曾在美國的一家 CDN 公司工作,當時我們的客戶也會有自己的運維團隊,他們沒事就去翻 CDN 提供的原始日誌。可能對我們來說是百分之一或者千分之一這樣的問題,但是對他們來說就是比較重要的問題,就會報告上來,我們則就必須去排查,必須去找出真正的原因,反饋給他們。這些實際存在的大量的現實問題,激發著新技術的發明和產生。
我覺得動態追蹤技術很了不起的一點就是,它是一種“活體分析”技術。就是說,我們的某個程式或者整個軟體系統仍然在執行,仍然線上上服務,還在處理真實請求的時候,我們就可以去對它進行分析(不管它自己願不願意),就像查詢一個資料庫一樣。這是非常有意思的。很多工程師容易忽略的一點是,正在執行的軟體系統本身其實就包含了絕大部分的寶貴資訊,就可以被直接當作是一個實時變化的資料庫來進行“查詢”。當然了,這種特殊的“資料庫”須是只讀的,否則我們的分析和除錯工作就有可能會影響到系統本身的行為,就可能會危害到線上服務。我們可以在作業系統核心的幫助下,從外部發起一系列有針對性的查詢,獲取關於這個軟體系統本身執行過程當中的許多第一手的寶貴的細節資訊,從而指導我們的問題分析和效能分析等很多工作。
動態追蹤技術通常是基於作業系統核心來實現的。作業系統核心其實可以控制整個軟體世界,因為它其實是處於“造物主”這樣的一個地位。它擁有絕對的許可權,同時它可以確保我們針對軟體系統發出的各種“查詢”不會影響到軟體系統本身的正常執行。換句話說,我們的這種查詢必須是足夠安全的,是可以在生產系統上大量使用的。把軟體系統作為“資料庫”進行查詢就會涉及到一個查詢方式的問題,顯然我們並不是透過 SQL 這樣的方式去查詢這種特殊的“資料庫”。
在動態追蹤裡面一般是透過探針這樣的機制來發起查詢。我們會在軟體系統的某一個層次,或者某幾個層次上面,安置一些探針,然後我們會自己定義這些探針所關聯的處理程式。這有點像中醫裡面的針灸,就是說如果我們把軟體系統看成是一個人,我們可以往他的一些穴位上扎一些“針”,那麼這些針頭上面通常會有我們自己定義的一些“感測器”,我們可以自由地採集所需要的那些穴位上的關鍵資訊,然後把這些資訊彙總起來,產生可靠的病因診斷和可行的治療方案。這裡的追蹤通常涉及兩個維度。一個是時間維度,因為這個軟體還一直在執行,它便有一個在時間線上的連續的變化過程。另一個維度則是空間維度,因為可能它涉及到多個不同的程序,包含核心程序,而每個程序經常會有自己的記憶體空間、程序空間,那麼在不同的層次之間,以及在同一層次的記憶體空間裡面,我可以同時沿縱向和橫向,獲取很多在空間上的寶貴資訊。這有點兒像蛛蛛在蛛網上搜尋獵物。

我們既可以在作業系統核心裡面拿一些資訊,也可以在使用者態程式等較高的層面上採集一些資訊。這些資訊可以在時間線上面關聯起來,構建出一幅完整的軟體圖景,從而有效地指導我們做一些很複雜的分析。這裡非常關鍵的一點是,它是非侵入式的。如果把軟體系統比作一個人,那我們顯然不想把一個活人開膛破肚,卻只是為了幫他診斷疾病。相反,我們會去給他拍一張 X 光,給他做一個核磁共振,給他號號脈,或者最簡單的,用聽診器聽一聽,諸如此類。針對一個生產系統的診斷,其實也應如此。動態追蹤技術允許我們使用非侵入式的方式,不用去修改我們的作業系統核心,不用去修改我們的應用程式,也不用去修改我們的業務程式碼或者任何配置,就可以快速高效地精確獲取我們想要的資訊,第一手的資訊,從而幫助定位我們正在排查的各種問題。
我覺得大部分工程師可能特別熟悉軟體構造的過程,這其實是咱的基本功了。我們通常會建立不同的抽象層次,一層一層的把軟體構造起來,無論是自底向上,還是自頂向下。建立軟體抽象層次的方式很多,比如透過物件導向裡面的類和方法,或者直接透過函式和子例程等方式。而除錯的過程,其實與軟體構造的方式剛好相反,我們恰恰是要能夠很輕易地“打破”原先建立起來的這些抽象層次,能夠隨心所欲的拿到任意一個或者任意幾個抽象層次上的任何所需的資訊,而不管甚麼封裝設計,不管甚麼隔離設計,不管任何軟體構造時人為建立的條條框框。這是因為除錯的時候總是希望能拿到儘可能多的資訊,畢竟問題可能發生在任何層面上。
正因為動態追蹤技術一般是基於作業系統核心的,而核心是“造物主”,是絕對的權威,所以這種技術可以輕而易舉地貫通各個軟體層次的抽象和封裝,因此軟體構造時建立的抽象和封裝層次其實並不會成為阻礙。相反,在軟體構造時建立起來的設計良好的抽象與封裝層次,其實反而有助於除錯過程,關於這點,我們後面還會專門提到。我在自己的工作當中經常會發現,有的工程師線上上出問題的時候,非常慌亂,會去胡亂猜測可能的原因,但又缺乏任何證據去支援或者否證他的猜測與假設。他甚至會線上上反覆地試錯,反覆地折騰,搞得一團亂麻,毫無頭緒,讓自己和身邊的同事都很痛苦,白白浪費了寶貴的排錯時間。當我們有了動態追蹤技術之後,排查問題本身就可能會變成一個非常有趣的過程,讓我們遇到線上的詭異問題就感到興奮,就彷彿好不容易又逮著機會,可以去解一道迷人的謎題。當然了,這一切的前提是,我們具有趁手的強大的工具,幫助我們進行資訊採集和推理,幫助我們快速證明或否證任何假設和推測。
動態追蹤的優點
動態追蹤技術一般是不需要目標應用來配合的。比如說,我們在給一個哥們做體檢的時候,他還在操場上奔跑,我們就能在他還在運動的過程中,直接給他拍一張動態的 X 光,而且他自己還不知道。仔細想一下,這其實是一件很了不起的事情。各種基於動態追蹤的分析工具的執行方式都是一種“熱插拔”的方式,就是說,我們隨時可以執行這個工具,隨時進行取樣,隨時結束取樣,而不用管目標系統的當前狀態。很多統計和分析,其實都是目標系統上線之後才想到的,我們並不可能在上線前預測未來可能會遇到哪些問題,更不可能預測我們需要採集的所有資訊,用以排查那些未知的問題。動態追蹤的好處就是,可以實現“隨時隨地,按需採集”。另外還有一個優勢是它自身的效能損耗極小。仔細寫出的除錯工具對系統的極限效能的影響,通常在百分之五,甚至更低的比例以下,所以它一般不會對我們的終端使用者產生可以觀察到的效能影響。另外,即使是這麼小的效能損耗也只發生在我們實際取樣的那幾十秒或者幾分鐘以內。一旦我們的除錯工具結束執行,線上系統又會自動恢復到原先百分之百的效能,繼續向前狂奔。

DTrace 與 SystemTap
說到動態追蹤就不能不提到 DTrace。DTrace 算是現代動態追蹤技術的鼻祖了,它於 21 世紀初誕生於 Solaris 作業系統,是由原來的 Sun Microsystems 公司的工程師編寫的。可能很多同學都聽說過 Solaris 系統和 Sun 公司的大名。
最初產生的時候,我記得有這樣一個故事,當時 Solaris 作業系統的幾個工程師花了幾天幾夜去排查一個看似非常詭異的線上問題。開始他們以為是很高階的問題,就特別賣力,結果折騰了幾天,最後發現其實是一個非常愚蠢的、某個不起眼的地方的配置問題。自從那件事情之後,這些工程師就痛定思痛,創造了 DTrace 這樣一個非常高階的除錯工具,來幫助他們在未來的工作當中避免把過多精力花費在愚蠢問題上面。畢竟大部分所謂的“詭異問題”其實都是低階問題,屬於那種“調不出來很鬱悶,調出來了更鬱悶”的型別。
應該說 DTrace 是一個非常通用的除錯平臺,它提供了一種很像 C 語言的指令碼語言,叫做 D。基於 DTrace 的除錯工具都是使用這種語言編寫的。D 語言支援特殊的語法用以指定“探針”,這個“探針”通常有一個位置描述的資訊。你可以把它定位在某個核心函式的入口或出口,抑或是某個使用者態程序的 函式入口或出口,甚至是任意一條程式語句或機器指令上面。編寫 D 語言的除錯程式是需要對系統有一定的瞭解和知識的。這些除錯程式是我們重拾對複雜系統的洞察力的利器。Sun 公司有一位前工程師叫做 Brendan Gregg,他是最初的 DTrace 的使用者,甚至早於 DTrace 被開源出來。Brendan 編寫了很多可以複用的基於 DTrace 的除錯工具,一齊放在一個叫做 DTrace Toolkit 的開源專案中。Dtrace 是最早的動態追蹤框架,也是最有名的一個。
DTrace 的優勢是它採取了跟作業系統核心緊密整合的一種方式。D 語言的實現其實是一個虛擬機器(VM),有點像 Java 虛擬機器(JVM)。它的一個好處在於 D 語言的執行時是常駐核心的,而且非常小巧,所以每個除錯工具的啟動時間和退出時間都很短。但是我覺得 DTrace 也是有明顯缺點的。其中一個讓我很難受的缺點是 D 語言缺乏迴圈結構,這導致許多針對目標程序中的複雜資料結構的分析工具很難編寫。雖然 DTrace 官方聲稱缺少迴圈的原因是為了避免過熱的迴圈,但顯然 DTrace 是可以在 VM 級別上面有效限制每一個迴圈的執行次數的。另外一個較大的缺點是,DTrace 對於使用者態程式碼的追蹤支援比較弱,沒有自動的載入使用者態除錯符號的功能,需要自己在 D 語言裡面宣告用到的使用者態 C 語言結構體之類的型別。1
DTrace 的影響是非常大的,很多工程師把它移植到其他的作業系統。比方說蘋果的 Mac OS X 作業系統上就有 DTrace 的移植。其實近些年釋出的每一臺蘋果筆記本或者桌上型電腦上面,都有現成的 dtrace 命令列工具可以呼叫,大家可以去在蘋果機器的命令列終端上嘗試一下。這是蘋果系統上面的一個 DTrace 的移植。FreeBSD 作業系統也有這樣一個 DTrace 的移植。只不過它並不是預設啟用的。你需要透過命令去載入 FreeBSD 的 DTrace 核心模組。Oracle 也有在它自己的 Oracle Linux 作業系統發行版當中開始針對 Linux 核心進行 DTrace 移植。不過 Oracle 的移植工作好像一直沒有多少起色,畢竟 Linux 核心並不是 Oracle 控制的,而 DTrace 是需要和作業系統核心緊密整合的。出於類似的原因,民間一些勇敢的工程師嘗試的 DTrace 的 Linux 移植也一直距離生產級別的要求很遠。
相比 Solaris 上面原生的 DTrace,這些 DTrace 移植都或多或少的缺乏某些高階特性,所以從能力上來說,還不及最本初的 DTrace。
DTrace 對 Linux 作業系統的另一個影響反映在 SystemTap 這個開源專案。這是由 Red Hat 公司的工程師建立的較為獨立的動態追蹤框架。SystemTap 提供了自己的一種小語言,和 D 語言並不相同。顯然,Red Hat 自己服務於非常多的企業級使用者,他們的工程師每天需要處理的各種線上的“詭異問題”自然也是極多的。這種技術的產生必然是現實需求激發的。我覺得 SystemTap 是目前 Linux 世界功能最強大,同時也是最實用的動態追蹤框架。我在自己的工作當中已經成功使用多年。SystemTap 的作者 Frank Ch. Eigler 和 Josh Stone 等人,都是非常熱情、同時非常聰明的工程師。我在 IRC 或者郵件列表裡的提問,他們一般都會非常快且非常詳盡地進行解答。值得一提的是,我也曾給 SystemTap 貢獻過一個較為重要的新特性,使其能在任意的探針上下文中訪問使用者態的全域性變數的取值。我當時合併到 SystemTap 主線的這個 C++ 補丁的規模達到了約一千行,多虧了 SystemTap 作者們的熱心幫助2。這個新特性在我基於 SystemTap 實現的動態指令碼語言(比如 Perl 和 Lua)的火焰圖工具中扮演了關鍵角色。
SystemTap 的優點是它有非常成熟的使用者態除錯符號的自動載入,同時也有迴圈這樣的語言結構可以去編寫比較複雜的探針處理程式,可以支援很多很複雜的分析處理。由於 SystemTap 早些年在實現上的不成熟,導致網際網路上充斥著很多針對它的已經過時了的詬病和批評。最近幾年 SystemTap 已然有了長足的進步。我在 2017 年創辦的 OpenResty Inc. 公司也對 SystemTap 做了非常大的增強和最佳化。
當然,SystemTap 也是有缺點的。首先,它並不是 Linux 核心的一部分,就是說它並沒有與核心緊密整合,所以它需要一直不停地追趕主線核心的變化。另一個缺點是,它通常是把它的“小語言”指令碼(有點像 D 語言哦)動態編譯成一個 Linux 核心模組的 C 原始碼,因此經常需要線上部署 C 編譯器工具鏈和 Linux 核心的標頭檔案。出於這些原因,SystemTap 指令碼的啟動相比 DTrace 要慢得多,和 JVM 的啟動時間倒有幾分類似。雖然存在這些缺點3,但總的來說,SystemTap 還是一個非常成熟的動態追蹤框架。

無論是 DTrace 還是 SystemTap,其實都不支援編寫完整的除錯工具,因為它們都缺少方便的命令列互動的原語。所以我們才看到現實世界中許多基於它們的工具,其實最外面都有一個 Perl、Python 或者 Shell 指令碼編寫的包裹。為了便於使用一種乾淨的語言編寫完整的除錯工具,我曾經給 SystemTap 語言進行了擴充套件,實現了一個更高層的“宏語言”,叫做 stap++4。我自己用 Perl 實現的 stap++ 直譯器可以直接解釋執行 stap++ 原始碼,並在內部呼叫 SystemTap 命令列工具。有興趣的朋友可以檢視我開源在 GitHub 上面的 stapxx 這個程式碼倉庫。這個倉庫裡面也包含了很多直接使用我的 stap++ 宏語言實現的完整的除錯工具。
SystemTap 在生產上的應用
DTrace 有今天這麼大的影響離不開著名的 DTrace 佈道士 Brendan Gregg 老師。前面我們也提到了他的名字。他最初是在 Sun Microsystems 公司,工作在 Solaris 的檔案系統最佳化團隊,是最早的 DTrace 使用者。他寫過好幾本有關 DTrace 和效能最佳化方面的書,也寫過很多動態追蹤方面的部落格文章。
2011 年我離開淘寶以後,曾經在福州過了一年所謂的“田園生活”。在田園生活的最後幾個月當中,我透過 Brendan 的公開部落格較為系統地學習了 DTrace 和動態追蹤技術。其實最早聽說 DTrace 是因為一位微博好友的評論,他只提到了 DTrace 這個名字。於是我便想了解一下這究竟是甚麼東西。誰知,不瞭解不知道,一瞭解嚇一跳。這竟然是一個全新的世界,徹底改變了我對整個計算世界的看法。於是我就花了非常多的時間,一篇一篇地仔細精讀 Brendan 的個人部落格。後來終於有一天,我有了一種大徹大悟的感覺,終於可以融會貫通,掌握到了動態追蹤技術的精妙。
2012 年我結束了在福州的“田園生活”,來到美國加入前面提到的那家 CDN 公司。然後我就立即開始著手把 SystemTap 以及我已領悟到的動態追蹤的一整套方法,應用到這家 CDN 公司的全球網路當中去,用於解決那些非常詭異非常奇怪的線上問題。我在這家公司觀察到其實很多工程師在排查線上問題的時候,經常會自己在軟體系統裡面埋點。這主要是在業務程式碼裡,乃至於像 Nginx 這樣的系統軟體的程式碼基(code base)裡,自己去做修改,新增一些計數器,或者去埋下一些記錄日誌的點。透過這種方式,大量的日誌會線上上被實時地採集起來,進入專門的資料庫,然後再進行離線分析。顯然這種做法的成本是巨大的,不僅涉及業務系統本身的修改和維護成本的陡然提高,而且全量採集和儲存大量的埋點資訊的線上開銷,也是非常可觀的。而且經常出現的情況是,張三今天在業務程式碼裡面埋了一個採集點,李四明天又埋下另一個相似的點,事後可能這些點又都被遺忘在了程式碼基裡面,而沒有人再去理會。最後這種點會越來越多,把程式碼基搞得越來越凌亂。這種侵入式的修改,會導致相應的軟體,無論是系統軟體還是業務程式碼,變得越來越難以維護。
埋點的方式主要存在兩大問題,一個是“太多”的問題,一個是“太少”的問題。“太多”是指我們往往會採集一些根本不需要的資訊,只是一時貪多貪全,從而造成不必要的採集和儲存開銷。很多時候我們透過取樣就能進行分析的問題,可能會習慣性的進行全網全量的採集,這種代價累積起來顯然是非常昂貴的。那“太少”的問題是指,我們往往很難在一開始就規劃好所需的所有資訊採集點,畢竟沒有人是先知,可以預知未來需要排查的問題。所以當我們遇到新問題時,現有的採集點蒐集到的資訊幾乎總是不夠用的。這就導致頻繁地修改軟體系統,頻繁地進行上線操作,大大增加了開發工程師和運維工程師的工作量,同時增加了線上發生更大故障的風險。
另外一種暴力除錯的做法也是我們某些運維工程師經常採用的,即把機器拉下線,然後設定一系列臨時的防火牆規則,以遮蔽使用者流量或者自己的監控流量,然後在生產機上各種折騰。這是很繁瑣影響很大的過程。首先它會讓機器不能再繼續服務,降低了整個線上系統的總的吞吐能力。同時有些只有真實流量才能復現的問題,此時再也無法復現了。可以想象這些粗暴的做法有多麼讓人頭疼。
實際上運用 SystemTap 動態追蹤技術可以很好地解決這樣的問題,有“潤物細無聲”之妙。首先我們不需要去修改我們的軟體棧(software stack)本身,不管是系統軟體還是業務軟體。我經常會編寫一些有針對性的工具,然後在一些關鍵的系統「穴位」上面放置一些經過仔細安排的探針。這些探針會採集各自的資訊,同時除錯工具會把這些資訊彙總起來輸出到終端。用這種方式我可以在某一臺機器或某幾臺機器上面,透過取樣的方式,很快地得到我想要的關鍵資訊,從而快速地回答一些非常基本的問題,給後續的除錯工作指明方向。
正如我前面提到的,與其在生產系統裡面人工去埋點去記日誌,再蒐集日誌入庫,還不如把整個生產系統本身看成是一個可以直接查詢的“資料庫”,我們直接從這個“資料庫”裡安全快捷地得到我們想要的資訊,而且絕不留痕跡,絕不去採集我們不需要的資訊。利用這種思想,我編寫了很多除錯工具,絕大部分已經開源在了 GitHub 上面,很多是針對像 Nginx、LuaJIT 和作業系統核心這樣的系統軟體,也有一些是針對更高層面的像 OpenResty 這樣的 Web 框架。有興趣的朋友可以檢視 GitHub 上面的 nginx-systemtap-toolkit、perl-systemtap-toolkit 和 stappxx 這幾個程式碼倉庫。

利用這些工具,我成功地定位了數不清的線上問題,有些問題甚至是我意外發現的。下面就隨便舉幾個例子吧。
第一個例子是,我使用基於 SystemTap 的火焰圖工具分析我們線上的 Nginx 程序,結果發現有相當一部分 CPU 時間花費在了一條非常奇怪的程式碼路徑上面。這其實是我一位同事在很久之前除錯一個老問題時遺留下來的臨時的除錯程式碼,有點兒像我們前面提到的“埋點程式碼”。結果它就這樣被遺忘在了線上,遺忘在了公司程式碼倉庫裡,雖然當時那個問題其實早已解決。由於這個代價高昂的“埋點程式碼”一直沒有去除,所以一直都產生著較大的效能損耗,而一直都沒有人注意到。所以可謂是我意外的發現。當時我就是透過取樣的方式,讓工具自動繪製出一張火焰圖。我一看這張圖就可以發現問題並能採取措施。這是非常非常有效的方式。
第二個例子是,很少量的請求存在延時較長的問題,即所謂的“長尾請求”。這些請求數目很低,但可能達到「秒級」這樣的延時。當時有同事亂猜說是我的 OpenResty 有 bug,我不服氣,於是立即編寫了一個 SystemTap 工具去線上進行取樣,對那些超過一秒總延時的請求進行分析。該工具會直接測試這些問題請求內部的時間分佈,包括請求處理過程中各個典型 I/O 操作的延時以及純 CPU 計算延時。結果很快定位到是 OpenResty 在訪問 Go 編寫的 DNS 伺服器時,出現延時緩慢。然後我再讓我的工具輸出這些長尾 DNS 查詢的具體內容,發現都是涉及 CNAME 展開。顯然,這與OpenResty 無關了,而進一步的排查和最佳化也有了明確的方向。
第三個例子是,我們曾注意到某一個機房的機器存在比例明顯高於其他機房的網路超時的問題,但也只有 1% 的比例。一開始我們很自然的去懷疑網路協議棧方面的細節。但後來我透過一系列專門的 SystemTap 工具直接分析那些超時請求的內部細節,便定位到了是硬碟 配置方面的問題。從網路到硬碟,這種除錯是非常有趣的。第一手的資料讓我們快速走上正確的軌道。
還有一個例子是,我們曾經透過火焰圖在 Nginx 程序裡觀察到檔案的開啟和關閉操作佔用了較多的 CPU 時間,於是我們很自然地啟用了 Nginx 自身的檔案控制代碼快取配置,但是最佳化效果並不明顯。於是再做出一張新的火焰圖,便發現因為這回輪到 Nginx 的檔案控制代碼快取的後設資料所使用的“自旋鎖”佔用很多 CPU 時間了。這是因為我們雖然啟用了快取,但把快取的大小設定得過大,所以導致後設資料的自旋鎖的開銷抵消掉了快取帶來的好處。這一切都能在火焰圖上面一目瞭然地看出來。假設我們沒有火焰圖,而只是盲目地試驗,很可能會得出 Nginx 的檔案控制代碼快取沒用的錯誤結論,而不會去想到去調整快取的引數。
最後一個例子是,我們在某一次上線操作之後,線上上最新的火焰圖中觀察到正規表示式的編譯操作佔用了很多 CPU 時間,但其實我們已經線上上啟用了正則編譯結果的快取。很顯然,我們業務系統中用到的正規表示式的數量,已然超出了我們最初設定的快取大小,於是很自然地想到把線上的正則快取調的更大一些。然後,我們線上上的火焰圖中便再看不到正則編譯操作了。
透過這些例子我們其實可以看到,不同的資料中心,不同的機器,乃至同一臺機器的不同時段,都會產生自己特有的一些新問題。我們需要的是直接對問題本身進行分析,進行取樣,而不是胡亂去猜測去試錯。有了強大的工具,排錯其實是一個事半功倍的事情。
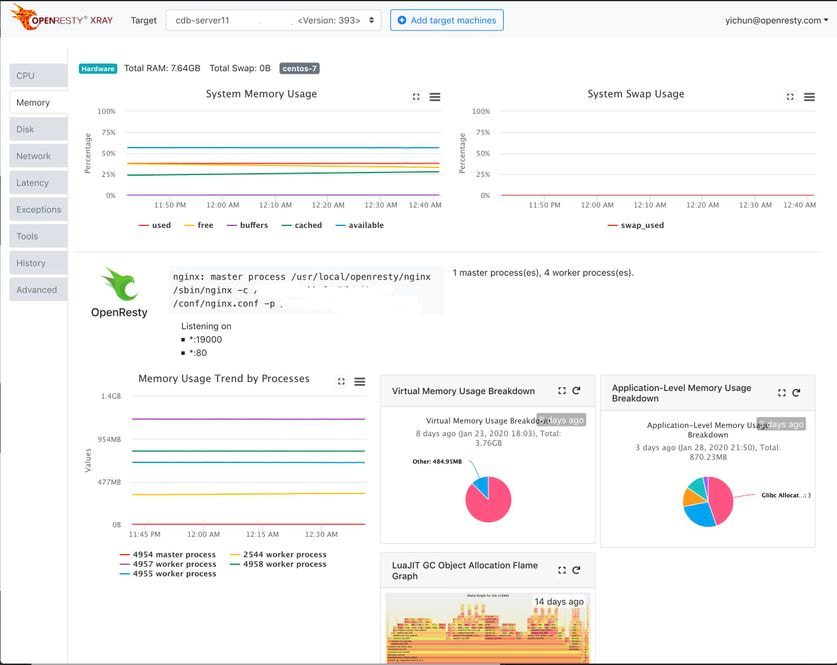
自從我們成立了 OpenResty Inc. 公司以後,我們研發了 OpenResty XRay 這一款全新一代的動態追蹤平臺。我們已經不再手動去使用 SystemTap 這樣的開源解決方案了。
火焰圖
前面我們已經多次提到了火焰圖(Flame Graph)這種東西,那麼火焰圖是甚麼呢?它其實是一個非常了不起的視覺化方法,是由前面已經反覆提到的 Brendan Gregg 同學發明的。
火焰圖就像是給一個軟體系統拍的 X 光照片,可以很自然地把時間和空間兩個維度上的資訊融合在一張圖上,以非常直觀的形式展現出來,從而反映系統在效能方面的很多定量的統計規律。

比方說,最經典的火焰圖是統計某一個軟體的所有程式碼路徑在 CPU 上面的時間分佈。透過這張分佈圖我們就可以直觀地看出哪些程式碼路徑花費的 CPU 時間較多,而哪些則是無關緊要的。進一步地,我們可以在不同的軟體層面上生成火焰圖,比如說可以在系統軟體的 C/C++ 語言層面上畫出一張圖,然後再在更高的——比如說——動態指令碼語言的層面,例如 Lua 和 Perl 程式碼的層面,畫出火焰圖。不同層面的火焰圖常常會提供不同的視角,從而反映出不同層面上的程式碼熱點。
因為我自己維護著 OpenResty 這樣的開源軟體的社群,我們有自己的郵件列表,我經常會鼓勵報告問題的使用者主動提供自己繪製的火焰圖,這樣我們就可以愜意地看圖說話,幫助使用者快速地進行效能問題的定位,而不至於反覆地試錯,和使用者一起去胡亂猜測,從而節約彼此大量的時間,皆大歡喜。
這裡值得注意的是,即使是遇到我們並不瞭解的陌生程式,透過看火焰圖,也可以大致推出效能問題的所在,即使從未閱讀過它的一行原始碼。這是一件非常了不起的事情。因為大部分程式其實是編寫良好的,也就是說它往往在軟體構造的時候就使用了抽象層次,比如透過函式。這些函式的名稱通常會包含語義上的資訊,並在火焰圖上面直接顯示出來。透過這些函式名,我們可以大致推測出對應的函式,乃至對應的某一條程式碼路徑,大致是做甚麼事情的,從而推斷出這個程式所存在的效能問題。所以,又回到那句老話,程式程式碼中的命名非常重要,不僅有助於閱讀原始碼,也有助於除錯問題。而反過來,火焰圖也為我們提供了一條學習陌生的軟體系統的捷徑。畢竟重要的程式碼路徑,幾乎總是花費時間較多的那些,所以值得我們重點研究;否則的話,這個軟體的構造方式必然存在很大的問題。
火焰圖其實可以拓展到其他維度,比如剛才我們講的火焰圖是看程式執行在 CPU 上的時間在所有程式碼路徑上的分佈,這是 on-CPU 時間這個維度。類似地,某一個程序不執行在任何 CPU 上的時間其實也是非常有趣的,我們稱之為 off-CPU 時間。off-CPU 時間一般是這個程序因為某種原因處於休眠狀態,比如說在等待某一個系統級別的鎖,或者被一個非常繁忙的程序排程器(scheduler)強行剝奪 CPU 時間片。這些情況都會導致這個程序無法執行在 CPU 上,但是仍然花費很多的掛鐘時間。透過這個維度的火焰圖我們可以得到另一幅很不一樣的圖景。透過這個維度上的資訊,我們可以分析系統鎖方面的開銷(比如 sem_wait 這樣的系統呼叫),某些阻塞的 I/O 操作(例如 open、read 之類),還可以分析程序或執行緒之間爭用 CPU 的問題。透過 off-CPU 火焰圖,都一目瞭然。
應該說 off-CPU 火焰圖也算是我自己的一個大膽嘗試。記得最初我在加州和內華達州之間的一個叫做 Tahoe 的湖泊邊,閱讀 Brendan 關於 off-CPU 時間的一篇部落格文章。我當然就想到,或許可以把 off-CPU 時間代替 on-CPU 時間應用到火焰圖這種展現方式上去。於是回來後我就在公司的生產系統中做了這樣一個嘗試,使用 SystemTap 繪製出了 Nginx 程序的 off-CPU 火焰圖。我在推特上公佈了這個成功嘗試之後,Brendan 還專門聯絡到我,說他自己之前也嘗試過這種方式,但效果並不理想。我估計這是因為他當時將之應用於多執行緒的程式,比如 MySQL,而多執行緒的程式因為執行緒同步方面的原因,off-CPU 圖上會有很多噪音,容易掩蓋真正有趣的那些部分。而我應用 off-CPU 火焰圖的場景是像 Nginx 這樣的單執行緒程式,所以 off-CPU 火焰圖裡往往會立即指示出那些阻塞 Nginx 事件迴圈的系統呼叫,抑或是 sem_wait 之類的鎖操作,又或者是搶佔式的程序排程器的強行介入,於是可以非常好地幫助分析一大類的效能問題。在這樣的 off-CPU 火焰圖中,唯一的“噪音”其實就是 Nginx 事件迴圈本身的 epoll_wait 這樣的系統呼叫,很容易識別並忽略掉。

類似地,我們可以把火焰圖拓展到其他的系統指標維度,比如記憶體洩漏的位元組數。有一回我就使用“記憶體洩漏火焰圖”快速定位了 Nginx 核心中的一處很微妙的洩漏問題。由於該洩漏發生在 Nginx 自己的記憶體池中,所以使用 Valgrind 和 AddressSanitizer 這樣的傳統工具是無法捕捉到的。還有一次也是使用“記憶體洩漏火焰圖”輕鬆定位了一位歐洲開發者自己編寫的 Nginx C 模組中的洩漏。那處洩漏非常細微和緩慢,困撓了他很久,而我幫他定位前都不需要閱讀他的原始碼。細想起來我自己都會覺得有些神奇。當然,我們也可以將火焰圖拓展到檔案 I/O 的延時和資料量等其他系統指標。所以這真是一種了不起的視覺化方法,可以用於很多完全不同的問題類別。
我們的 OpenResty XRay 產品支援自動取樣各種型別的火焰圖,包括 C/C++ 級別火焰圖、Lua 級別火焰圖、off-CPU 和 on-CPU 火焰圖、記憶體動態分配火焰圖、記憶體物件引用關係火焰圖、檔案 IO 火焰圖、等等。
方法論
前面我們介紹到火焰圖這樣的基於取樣的視覺化方法,它其實算是非常通用的方法了。不管是甚麼系統,是用甚麼語言編寫的,我們一般都可以得到一張某種效能維度上的火焰圖,然後輕鬆進行分析。但更多的時候,我們可能需要對一些更深層次的更特殊的問題進行分析和排查,此時就需要編寫一系列專門化的動態追蹤工具,有計劃有步驟地去逼近真正的問題。
在這個過程當中,我們推薦的策略是一種所謂的小步推進、連續求問的方式。也就是說我們並不指望一下編寫一個很龐大很複雜的除錯工具,一下子採集到所有可能需要的資訊,從而一下子解決掉最終的問題。相反,我們會把最終問題的假設,分解成一系列的小假設,然後逐步求索,逐步驗證,不斷確定會修正我們的方向,不斷地調整我們的軌跡和我們的假設,以接近最終的問題。這樣做有一個好處是,每一個步驟每一個階段的工具都可以足夠的簡單,那麼這些工具本身犯錯的可能性就大大降低。Brendan 也注意到他如果嘗試編寫多用途的複雜工具,這種複雜工具本身引入 bug 的可能性也大大提高了。而錯誤的工具會給出錯誤的資訊,從而誤導我們得出錯誤的結論。這是非常危險的。簡單工具的另一大好處是,在取樣過程當中對生產系統產生的開銷也會相對較小,畢竟引入的探針數目較少,每個探針的處理程式也不會有太多太複雜的計算。這裡的每一個除錯工具都有自己的針對性,都可以單獨使用,那麼這些工具在未來得到複用的機會也大大提高。所以總的來說,這種除錯策略是非常有益的。
值得一提的是,這裡我們拒絕所謂的“大資料”的除錯做法。即我們並不會去嘗試一下子採集儘可能全的資訊和資料。相反,我們在每一個階段每一個步驟上只採集我們當前步驟真正需要的資訊。在每一步上,基於我們已經採集到的資訊,去支援或者修正我們原來的方案和原來的方向,然後去指導編寫下一步更細化的分析工具。
另外,對於非常小頻率發生的線上事件,我們通常會採用“守株待兔”的做法,也就是說我們會設一個閾值或其他篩選條件,坐等有趣的事件被我們的探針捕獲到。比如在追蹤小頻率的大延時請求的時候,我們會在除錯工具裡,首先篩選出那些延時超過一定閾值的請求,然後針對這些請求,採集儘可能多的實際需要的細節資訊。這種策略其實跟我們傳統的儘可能多的採集全量統計資料的做法完全相反,正因為我們是有針對性地、有具體策略地進行取樣分析,我們才能把損耗和開銷降到最低點,避免無謂的資源浪費。
我們的 OpenResty XRay 產品透過知識庫和推理引擎,可以自動化應用各種動態追蹤方面的方法論,可以自動使用系統性的方法,逐步縮小問題範圍,直至定位問題根源,再報告給使用者,並向使用者建議最佳化或修復方法。
知識就是力量
我覺得動態追蹤技術很好地詮釋了一句老話,那就是“知識就是力量”。
透過動態追蹤工具,我們可以把我們原先對系統的一些認識和知識,轉變成可以解決實際問題的非常實用的工具。我們原先在計算機專業教育當中,透過課本瞭解到的那些原本抽象的概念,比如說虛擬檔案系統、虛擬記憶體系統、程序排程器等等,現在都可以變得非常鮮活和具體。我們第一次可以在實際的生產系統當中,真切地觀察它們具體的運作,它們的統計規律,而不用把作業系統核心或者系統軟體的原始碼改得面目全非。這些非侵入式的實時觀測的能力,都得益於動態追蹤技術。
這項技術就像是金庸小說裡楊過使的那把玄鐵重劍,完全不懂武功的人自然是使不動的。但只要會一些武功,就可以越使越好,不斷進步,直至木劍也能橫行天下的境界。所以但凡你有一些系統方面的知識,就可以把這把“劍”揮動起來,就可以解決一些雖然基本但原先都無法想象的問題。而且你積累的系統方面的知識越多,這把“劍”就可以使得越好。而且,還有一點很有意思的是,你每多知道一點,就立馬能多解決一些新的問題。反過來,由於我們可以透過這些除錯工具解決很多問題,可以測量和學習到生產系統裡面很多有趣的微觀或宏觀方面的統計規律,這些看得見的成果也會成為我們學習更多的系統知識的強大動力。於是很自然地,這也就成為有追求的工程師的“練級神器”。
記得我在微博上面曾經說過,“鼓勵工程師不斷的深入學習的工具才是有前途的好工具”。這其實是一個良性的相互促進的過程。
開源與除錯符號
前面我們提到,動態追蹤技術可以把正在執行的軟體系統變成一個可以查詢的實時只讀資料庫,但是做到這一點通常是有條件的,那就是這個軟體系統得有比較完整的除錯符號。那麼除錯符號是甚麼呢?除錯符號一般是軟體在編譯的時候,由編譯器生成的供除錯使用的元資訊。這些資訊可以把編譯後的二進位制程式裡面的很多細節資訊,比如說函式和變數的地址、資料結構的記憶體佈局等等,對映回原始碼裡面的那些抽象實體的名稱,比如說函式名、變數名、型別名之類。Linux 世界常見的除錯符號的格式稱為 DWARF(與英文單詞“矮人”相同)。正是因為有了這些除錯符號,我們在冰冷黑暗的二進位制世界裡面才有了一張地圖,才有了一座燈塔,才可能去解釋和還原這個底層世界裡每一個細微方面的語義,重建出高層次的抽象概念和關係。

通常也只有開源軟體才容易生成除錯符號,因為絕大多數閉源軟體出於保密方面的原因,並不會提供任何除錯符號,以增加逆向工程和破解的難度。其中有一個例子是 Intel 公司的 IPP 這個程式庫。IPP 針對 Intel 的晶片提供了很多常見演算法的最佳化實現。我們也曾經嘗試過在生產系統上面去使用基於 IPP 的 gzip 壓縮庫,但不幸的是我們遇到了問題—— IPP 會時不時的線上上崩潰。顯然,沒有除錯符號的閉源軟體在除錯的時候會非常痛苦。我們曾經跟 Intel 的工程師遠端溝通了好多次都沒有辦法定位和解決問題,最後只好放棄。如果有原始碼,或者有除錯符號,那麼這個除錯過程很可能會變的簡單許多。
關於開源與動態追蹤技術之間這種水乳相容的關係,Brendan Gregg 在他之前的一次分享當中也有提及。特別是當我們的整個軟體棧(software stack)都是開源的時候,動態追蹤的威力才有可能得到最大限度的發揮。軟體棧通常包括作業系統核心、各種系統軟體以及更上層的高階語言程式。當整個棧全部開源的時候,我們就可以輕而易舉的從各個軟體層面得到想要的資訊,並將之轉化為知識,轉化為行動方案。

由於較複雜的動態追蹤都會依賴於除錯符號,而有些 C 編譯器生成的除錯符號是有問題的。這些含有錯誤的除錯資訊會導致動態追蹤的效果打上很大的折扣,甚至直接阻礙我們的分析。比方說使用非常廣泛的 GCC 這個 C 編譯器,在 4.5 這個版本之前生成的除錯符號質量是很差的,而 4.5 之後則有了長足的進步,尤其是在開啟編譯器最佳化的情況下。
我們的 OpenResty XRay 動態追蹤平臺會實時抓取公網上常見的開源軟體的除錯符號包和二進位制包,並進行分析和索引。目前這個資料庫已經索引了幾十 TB 的資料了。
Linux 核心的支援
前面提到,動態追蹤技術一般是基於作業系統核心的,而對於我們平時使用非常廣泛的 Linux 作業系統核心來說,其動態追蹤的支援之路是一個漫長而艱辛的過程。其中一個主要原因或許是因為 Linux 的老大 Linus 一直覺得這種技術沒有必要。
最初 Red Hat 公司的工程師為 Linux 核心準備了一個所謂的 utrace 的補丁,用來支援使用者態的動態追蹤技術。這是 SystemTap 這樣的框架最初仰賴的基礎。在漫長的歲月裡,Red Hat 家族的 Linux 發行版都預設包含了這個 utrace 補丁,比如 RHEL、CentOS 和 Fedora 之類。在那段 utrace 主導的日子裡,SystemTap 只在 Red Hat 系的作業系統中有意義。這個 utrace 補丁最終也未能合併到主線版本的 Linux 核心中,它被另一種折衷的方案所取代。
Linux 主線版本很早就擁有了 kprobes 這種機制,可以動態地在指定的核心函式的入口和出口等位置上放置探針,並定義自己的探針處理程式。
使用者態的動態追蹤支援姍姍來遲,經歷了無數次的討論和反覆修改。從官方 Linux 核心的 3.5 這個版本開始,引入了基於 inode 的 uprobes 核心機制,可以安全地在使用者態函式的入口等位置設定動態探針,並執行自己的探針處理程式。再後來,從 3.10 的核心開始,又融合了所謂的 uretprobes 這個機制5,可以進一步地在使用者態函式的返回地址上設定動態探針。uprobes 和 uretprobes 加在一起,終於可以取代 utrace 的主要功能。utrace 補丁從此也完成了它的歷史使命。而 SystemTap 現在也能在較新的核心上面,自動使用 uprobes 和 uretprobes 這些機制,而不再依賴於 utrace 補丁。
最近幾年 Linux 的主線開發者們,把原來用於防火牆的 netfilter 裡所使用的動態編譯器,即 BPF,擴充套件了一下,得到了一個所謂的 eBPF,可以作為某種更加通用的核心虛擬機器。透過這種機制,我們其實可以在 Linux 中構建類似 DTrace 那種常駐核心的動態追蹤虛擬機器。而事實上,最近已經有了一些這方面的嘗試,比如說像 BPF 編譯器(BCC)這樣的工具,使用 LLVM 工具鏈來把 C 程式碼編譯為 eBPF 虛擬機器所接受的位元組碼。總的來說,Linux 的動態追蹤支援是變得越來越好的。特別是從 3.15 版本的核心開始,動態追蹤相關的核心機制終於變得比較健壯和穩定了。可惜的是,eBPF 在設計上一直有嚴重的限制,使得那些基於 eBPF 開發的動態追蹤工具始終停留在較為簡單的水平上,用我的話來說,還停留在“石器時代”。雖然 SystemTap 最近也開始支援 eBPF 這個執行時,但這個執行時支援的 stap 語言特性也是極為有限的,即使 SystemTap 的老大 Frank 也表達了這方面的擔心。
硬體追蹤
我們看到動態追蹤技術在軟體系統的分析當中可以扮演非常關鍵的角色,那麼很自然地會想到,是否也可以用類似的方法和思想去追蹤硬體。
我們知道其實作業系統是直接和硬體打交道的,那麼透過追蹤作業系統的某些驅動程式或者其他方面,我們也可以間接地去分析與之相接的硬體裝置的一些行為和問題。同時,現代硬體,比如說像 Intel 的 CPU,一般會內建一些效能統計方面的暫存器(Hardware Performance Counter),透過軟體讀取這些特殊暫存器裡的資訊,我們也可以得到很多有趣的直接關於硬體的資訊。比如說 Linux 世界裡的 perf 工具最初就是為了這個目的。甚至包括 VMWare 這樣的虛擬機器軟體也會去模擬這樣特殊的硬體暫存器。基於這種特殊暫存器,也產生了像 Mozilla rr 這樣有趣的除錯工具,可以高效地進行程序執行過程的錄製與回放。
直接對硬體內部設定動態探針並實施動態追蹤,或許目前還存在於科幻層面,歡迎有興趣的同學能夠貢獻更多的靈感和資訊。
死亡程序的遺骸分析
我們前面看到的其實都是對活著的程序進行分析,或者說正在執行的程式。那麼死的程序呢?對於死掉的程序,其實最常見的形式就是程序發生了異常崩潰,產生了所謂的 core dump 檔案。其實對於這樣死掉的程序剩下的“遺骸”,我們也可以進行很多深入的分析,從而有可能確定它的死亡原因。從這個意義上來講,我們作為程式設計師扮演著「法醫」這樣的角色。
最經典的針對死程序遺骸進行分析的工具便是鼎鼎大名的 GNU Debugger(GDB)。那麼 LLVM 世界也有一個類似的工具叫做 LLDB。顯然,GDB 原生的命令語言是非常有侷限的,我們如果手工逐條命令地對 core dump 進行分析其實能得到地資訊也非常有限。其實大部分工程師分析 core dump 也只是用 bt full 命令檢視一下當前的 C 呼叫棧軌跡,抑或是利用 info reg 命令檢視一下各個 CPU 暫存器的當前取值,又或者檢視一下崩潰位置的機器程式碼序列,等等。而其實更多的資訊深藏於在堆(heap)中分配的各種複雜的二進位制資料結構之中。對堆裡的複雜資料結構進行掃描和分析,顯然需要自動化,我們需要一種可程式設計的方式來編寫複雜的 core dump 的分析工具。
順應此需求,GDB 在較新的版本當中(我記得好像是從 7.0 開始的),內建了對 Python 指令碼的支援。我們現在可以用 Python 來實現較複雜的 GDB 命令,從而對 core dump 這樣的東西進行深度分析。事實上我也用 Python 寫了很多這樣的基於 GDB 的高階除錯工具,甚至很多工具是和分析活體程序的 SystemTap 工具一一對應起來的。與動態追蹤類似,藉助於除錯符號,我們可以在黑暗的“死亡世界”中找到光明之路。

不過這種做法帶來的一個問題是,工具的開發和移植變成了一個很大的負擔。用 Python 這樣的指令碼語言來對 C 風格的資料結構進行遍歷並不是一件有趣的事情。這種奇怪的 Python 程式碼寫多了真的會讓人抓狂。另外,同一個工具,我們既要用 SystemTap 的指令碼語言寫一遍,然後又要用 GDB 的 Python 程式碼來寫一遍:無疑這是一個很大的負擔,兩種實現都需要仔細地進行開發和測試。它們雖然做的是類似的事情,但實現程式碼和相應的 API 都完全不同(這裡值得一提的是,LLVM 世界的 LLDB 工具也提供了類似的 Python 程式設計支援,而那裡的 Python API 又和 GDB 的不相相容)。
我們當然也可以用 GDB 對活體程式進行分析,但和 SystemTap 相比,GDB 最明顯的就是效能問題。我曾經比較過一個較複雜工具的 SystemTap 版和 GDB Python 版。它們的效能相差有一個數量級。GDB 顯然不是為這種線上分析來設計的,相反,更多地考慮了互動性的使用方式。雖然它也能以批處理的方式執行,但是內部的實現方式決定了它存在非常嚴重的效能方面的限制。其中最讓我抓狂的莫過於 GDB 內部濫用 longjmp 來做常規的錯誤處理,從而帶來了嚴重的效能損耗,這在 SystemTap 生成的 GDB 火焰圖上是非常明顯的。幸運地是,對死程序的分析總是可以離線進行,我們沒必要線上去做這樣的事情,所以時間上的考慮倒並不是那麼重要了。然而不幸的是,我們的一些很複雜的 GDB Python 工具,需要執行好幾分鐘,即使是離線來做,也是讓人感到很挫敗的。
我自己曾經使用 SystemTap 對 GDB + Python 進行效能分析,並根據火焰圖定位到了 GDB 內部最大的兩處執行熱點。然後,我給 GDB 官方提了兩個 C 補丁,一是針對 Python 字串操作,一是針對 GDB 的錯誤處理方式。它們使得我們最複雜的 GDB Python 工具的整體執行速度提高了 100%。GDB 官方目前已經合併了其中一個補丁。使用動態追蹤技術來分析和改進傳統的除錯工具,也是非常有趣的。
我已經把很多從前在自己的工作當中編寫的 GDB Python 的除錯工具開源到了 GitHub 上面,有興趣的同學可以去看一下。一般是放在 nginx-gdb-utils 這樣的 GitHub 倉庫裡面,主要針對 Nginx 和 LuaJIT。我曾經利用這些工具協助 LuaJIT 的作者 Mike Pall 定位到了十多個 LuaJIT 內部的 bug。這些 bug 大多隱藏多年,都是 Just-in-Time (JIT) 編譯器中的很微妙的問題。
由於死掉的程序不存在隨時間變化的可能性,我們姑且把這種針對 core dump 的分析稱之為“靜態追蹤”吧。

我們的 OpenResty XRay 產品透過 Y 語言 編譯器,可以讓各種用 Y 語言編寫的分析工具也能同時支援 GDB 這樣的平臺,從而自動化對 core dump 檔案的深入分析。
傳統的除錯技術
說到 GDB,我們就不得不說一說動態追蹤與傳統的除錯方法之間的區別與聯絡。細心的有經驗的工程師應該會發現,其實動態追蹤的“前身”就是在 GDB 裡面設定斷點,然後在斷點處進行一系列檢查的這種方式。只不過不同的是,動態追蹤總是強調非互動式的批處理,強調儘可能低的效能損耗。而 GDB 這樣的工具天然就是為互動操作而生的,所以實現並不考慮生產安全性,也不怎麼在乎效能損耗。一般它的效能損耗是極大的。同時 GDB 所基於的 ptrace 這種很古老的系統呼叫,其中的坑和問題也非常多。比如 ptrace 需要改變目標除錯程序的父親,還不允許多個除錯者同時分析同一個程序。所以,從某種意義上來講,使用 GDB 可以模擬一種所謂的“窮人的動態追蹤”。
很多程式設計初學者喜歡使用 GDB 進行“單步執行”,而在真實的工業界的生產開發當中,這種方式經常是非常缺乏效率的。這是因為單步執行的時候往往會產生程式執行時序上的變化,導致很多與時序相關的問題無法再復現。另外,對於複雜的軟體系統,單步執行很容易讓人迷失在紛繁的程式碼路徑當中,或者說迷失在所謂的“花園小徑”當中,只見樹木,不見森林。
所以,對於日常的開發過程當中的除錯,其實我們還是推薦最簡單也是看起來最笨的方法,即在關鍵程式碼路徑上列印輸出語句。這樣我們透過檢視日誌等輸出得到一個有很完整的上下文,從而能夠有效進行分析的程式執行結果。當這種做法與測試驅動的開發方式結合起來的時候,尤為高效。顯然,這種加日誌和埋點的方式對於線上除錯是不切合實際的,關於這一點,前面已經充分地討論了。而另一方面,傳統的效能分析工具,像 Perl 的 DProf、C 世界裡的 gprof、以及其他語言和環境的效能分析器(profiler),往往需要用特殊的選項重新編譯程式,或者以特殊的方式重新執行程式。這種需要特別處理和配合的效能分析工具,顯然並不適用線上的實時活體分析。
凌亂的除錯世界
當今的除錯世界是很凌亂的,正如我們前面看到的有 DTrace、SystemTap、eBPF/BCC、GDB、LLDB 這些,還有很多很多我們沒有提到的,大家都可以在網路上查到。或許這從一個側面反映出了我們所處的這個真實世界的混亂。
之前有很多年我都在想,我們可以設計並實現一種大一統的除錯語言。後來我在 OpenResty Inc. 公司終於實現了這樣的一種語言,叫做 Y 語言。它的編譯器能夠自動生成各種不同的除錯框架和技術所接受的輸入程式碼。比如說生成 DTrace 接受的 D 語言程式碼,生成 SystemTap 接受的 stap 指令碼,還有 GDB 接受的 Python 指令碼,以及 LLDB 的另一種不相容 API 的 Python 指令碼,抑或是 eBPF 接受的位元組碼,乃至 BCC 接受的某種 C 和 Python 程式碼的混合物。
如果我們設計的一個除錯工具需要移植到多個不同的除錯框架,那麼顯然人工移植的工作量是非常大的,正如我前面所提到的。而如果有這樣一個大一統的 Y 語言,其編譯器能夠自動把同一份 Y 程式碼轉換為針對各種不同除錯平臺的輸入程式碼,並針對那些平臺進行自動最佳化,那麼每一種除錯工具我們就只需要用 Y 語言寫一遍就可以了。這將是巨大的解脫。而作為除錯者本人,也沒有必要親自去學習所有那些具體的除錯技術的凌亂的細節,親自去踩每一種除錯技術的“坑”。
Y 語言目前已經作為 OpenResty XRay 產品的一部分,提供給廣大使用者。
有朋友可能要問為甚麼要叫做 Y 呢? 這是因為我的名字叫亦春,而亦字的漢語拼音的第一個字母就是 Y……當然了,還有更重要的原因,那就是它是用來回答以「為甚麼」開頭的問題的語言,而「為甚麼」在英語裡面就是「why」,而 why 與 Y 諧音。
OpenResty XRay
OpenResty XRay 是由 OpenResty Inc. 公司提供的商業產品。OpenResty XRay 可以在無需目標程式任何配合的情況下,幫助使用者深入洞察其線上或者線下的各種軟體系統的行為細節,有效地分析和定位各種效能問題、可靠性問題和安全問題。在技術上,它擁有比 SystemTap 更強的追蹤功能,同時在效能上和易用性上也比 SystemTap 提高很多。它同時也可以支援自動分析 core dump 檔案這樣的程式遺骸。
有興趣的朋友歡迎聯絡我們,申請免費試用。
瞭解更多
如果你還想了解更多關於動態追蹤的技術、工具、方法論和案例,可以關注我們 OpenResty Inc. 公司的部落格網站 。也歡迎掃碼關注我們的微信公眾號:

同時非常歡迎大家試用我們的 OpenResty XRay 商業產品。
動態追蹤方面的先驅,Brendan Gregg 老師的部落格也有很多精采內容。
鳴謝
本文得到了我的很多朋友和家人的幫助。首先要感謝師蕊辛苦的聽寫筆錄工作;本文其實源自一次長達一小時的語音分享。然後要感謝很多朋友認真的審稿和意見反饋。同時也感謝我的父親和妻子在文字上的耐心幫助。
關於作者
章亦春是開源 OpenResty® 專案創始人兼 OpenResty Inc. 公司 CEO 和創始人。
章亦春(Github ID: agentzh),生於中國江蘇,現定居美國灣區。他是中國早期開源技術和文化的倡導者和領軍人物,曾供職於多家國際知名的高科技企業,如 Cloudflare、雅虎、阿里巴巴, 是 “邊緣計算“、”動態追蹤 “和 “機器程式設計 “的先驅,擁有超過 22 年的程式設計及 16 年的開源經驗。作為擁有超過 4000 萬全球域名使用者的開源專案的領導者。他基於其 OpenResty® 開源專案打造的高科技企業 OpenResty Inc. 位於美國矽谷中心。其主打的兩個產品 OpenResty XRay(利用動態追蹤技術的非侵入式的故障剖析和排除工具)和 OpenResty Edge(最適合微服務和分散式流量的全能型閘道器軟體),廣受全球眾多上市及大型企業青睞。在 OpenResty 以外,章亦春為多個開源專案貢獻了累計超過百萬行程式碼,其中包括,Linux 核心、Nginx、LuaJIT、GDB、SystemTap、LLVM、Perl 等,並編寫過 60 多個開源軟體庫。
譯文
我們提供了英譯版和中文原文(本文) 。我們歡迎讀者提供其他語言的翻譯版本,只要是全文翻譯不帶省略,我們都將會考慮採用,非常感謝!
SystemTap 和 OpenResty XRay 都沒有這些限制和缺點。 ↩︎
在我成立 OpenResty Inc. 公司之後,我們團隊也給開源 SystemTap 專案貢獻過數量眾多的補丁,從新功能到 bug 修復。 ↩︎
OpenResty XRay 的動態追蹤平臺並不存在 SystemTap 的這些缺點。 ↩︎
stap++ 專案不再繼續維護,已被使用全新一代動態追蹤技術的 OpenResty XRay 平臺和工具集所取代。 ↩︎
uretprobes 其實在實現上有很大的問題,因為它會直接修改目標程式的系統執行時棧,從而會破壞很多重要的功能,比如 stack unwinding。我們的 OpenResty XRay 自己重新實現了類似 uretprobes 的效果,但卻沒有它的這些缺點。 ↩︎
相關文章
OpenResty XRay Mar 3, 2026

OpenResty XRay Sep 24, 2025

OpenResty XRay Jul 1, 2025

OpenResty XRay Jun 27, 2025

OpenResty XRay Jun 27, 2025

















