Ylang: eBPF、Stap+、GDB などのフレームワーク向け汎用言語(第3回、全4回)
本記事は「Ylang:eBPF、Stap+、GDB などに適用可能な汎用言語」シリーズの第3回です。第1回、第2回、第4回もご参照ください。
Ylang の文法(前回の続き)
文字列
Ylang は C 言語の文字列リテラル構文(ダブルクォーテーションで囲まれた文字列)をサポートしています。
ただし、各 Ylang プログラムには2つのメモリ空間があることに注意が必要です。デフォルトでは、文字列リテラルはトレーサー空間内の Ylang 組み込み文字列として存在します。これらの文字列リテラルのアドレスを取得しようとすると、Ylang は自動的にトレース対象のメモリ空間(つまり、ターゲットプロセス)内で正確なリテラル文字列を検索し、トレース対象空間内のアドレスを返します。
const char *s = "hello, world\n";
バックグラウンドでは、Ylang はターゲットプロセスの .rodata セクションをスキャンし、一致する文字列の仮想メモリアドレス(最初の一致のみ有効)を返します。一致するものが見つからない場合、Ylang コンパイラはコンパイル時エラーを発生させます。通常、.rodata セクションのデータは OpenResty XRay のデータベースパッケージインデックスによって索引付けされており、Ylang コンパイラが毎回ターゲット実行ファイルを解析する必要はありません。
組み込み正規表現サポート
Ylang では、Perl 互換の正規表現(regexes)がネイティブにサポートされています。Perl 正規表現構文の多くの標準機能がサポートされています。Ylang は OpenResty 正規表現最適化コンパイラを使用して、ユーザーの正規表現から効率的なコードを生成します。当社独自のオートマトンアルゴリズムにより、入力文字列の長さに対して線形のマッチング時間が保証され、入力文字列の内容やサイズに関係なく、メモリ使用量は常に一定に保たれます。
以下は例です:
_probe _oneshot {
_str a = "hello, world";
if (a !~~ rx/^([a-z]+), ([a-z]+)$/) {
_error("not matched");
}
_print("0: ", $0, ", 1: ", $1, ", 2: ", $2, "\n");
}
この Ylang プログラムを実行すると、以下の出力が得られます:
$ run-y test.y
Start tracing...
0: hello, world, 1: hello, 2: world
正規表現全体にマッチする部分文字列を捕捉するために特殊変数 $0 を使用し、サブマッチングのグループを捕捉するために $1、$2 を使用します。
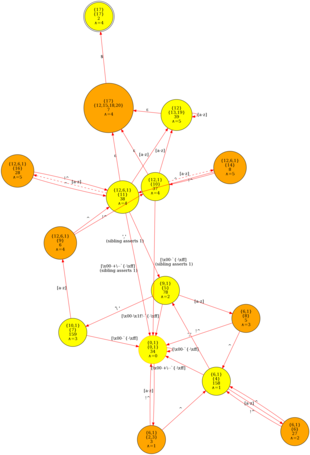
OpenResty の正規表現コンパイラは、以下のような最小決定性有限オートマトン(DFA)を構築することができます:
完全な制御フロー機能のサポート
Ylang は、for、while、do while、if、else、switch/case、break、continue など、C 言語のすべての制御フロー文をサポートしています。さらに、C 言語の goto 文も Ylang のすべてのバックエンド(Stap+、eBPF、ODB、GDB)で動作します。また、再帰的な関数呼び出しもサポートされています。以下は LuaJIT のソースコードツリーからの C コードのスニペットであり、有効な Ylang コードの例でもあります。
restart:
lname = debug_varname(pt, proto_bcpos(pt, ip), slot);
if (lname != NULL) { @name[0] = lname; return "local"; }
while (--ip > proto_bc(pt)) {
BCIns ins = *ip;
BCOp op = bc_op(ins);
BCReg ra = bc_a(ins);
if (bcmode_a(op) == BCMbase) {
if (slot >= ra && (op != BC_KNIL || slot <= bc_d(ins)))
return NULL;
} else if (bcmode_a(op) == BCMdst && ra == slot) {
switch (bc_op(ins)) {
case BC_MOV:
if (ra == slot) { slot = bc_d(ins); goto restart; }
break;
default:
return NULL;
}
}
Ylang における全てのループは有限であり、汎用的な goto 文も含まれます。各プローブハンドラーは、設定可能な制限内で限られた数の Ylang ステートメントの実行のみが許可されています。さらに、再帰関数呼び出しの深さは、ユーザーが調整可能な閾値によって制限されています。Ylang コンパイラは、Ylang プログラムが迅速に終了し、限られたスタックサイズで動作することを保証します。本質的に、Y コンパイラが生成するツールのための、非常に効率的な実行時サンドボックスを実現しています。
注目すべき点として、eBPF では最小限のループ構造しか持たず、ループはコンパイル時に展開される必要があります。オープンソースの eBPF C 言語では一般的なループ、特に後方ジャンプ (backward jumping) が禁止されています。これにより、対象アプリケーションでのコード再利用が非常に困難になるだけでなく、検証済みの重要な C コードの制御フローを書き直すことは非常にエラーが発生しやすくなります。動的トレーシング ツール自体のデバッグは困難であり、標準の eBPF バリデータは実行される eBPF 命令の総数の推定において効果的ではありません。例えば、大きな switch 文は、単一の case 文の実行に数個の命令しか使用しないにもかかわらず、100万命令という制限を超える可能性があります。OpenResty XRay の eBPF 実装にはこれらの制限がなく、Ylang プログラム自体にエラーがある場合でも、全ての Ylang プログラムが本番環境で常に安全に実行されることを保証します。
DTrace の D 言語にはループ構造が一切なく、DTrace ユーザーは自身でループを展開する必要があります。
オープンソースの SystemTap は非常に柔軟な制御フロー文を持っていますが、goto 文が欠如しています。一方、OpenResty XRay の Stap+ ツールチェーンにはそのような制限はありません。
浮動小数点数のサポート
Ylang のすべてのバックエンドは浮動小数点数をサポートしています。float と double という2つの C データ型は、トレーサー空間とトレーシー空間の両方で使用可能です。
以下は、トレーサー空間で浮動小数点数演算を行う例です:
double a = 3.1234512345123451234;
double b = 1.8123451234512345123;
_probe _oneshot(void) {
printf("a + b: %.15f\n", a + b);
printf("b + a: %.15f\n", b + a);
printf("a - b: %.15f\n", a - b);
printf("b - a: %.15f\n", b - a);
}
これを run-y ツールで実行します:
$ run-y test.y
Start tracing...
a + b: 4.935796357963580
b + a: 4.935796357963580
a - b: 1.311106111061111
b - a: -1.311106111061111
トレーシー space においても、対象プロセスのメモリから浮動小数点数を読み取ることができます。対象となる C プログラムに以下のような構造体型の変数があると仮定します:
typedef struct foo {
double d;
float f;
} foo;
foo obj = { 3.14, -0.01 };
int main(void) {
return 0;
}
この構造体には double 型のフィールドと float 型のフィールドが含まれています。以下の Ylang コードでこれらのフィールドを読み取ります:
_target static foo obj;
_probe main() {
printf(".d: %f\n", obj.d);
printf(".f: %f\n", obj.f);
}
この Ylang プログラムの出力は以下の通りです:
$ run-y -c ./a.out test.y
Start tracing...
.d: 3.140000
.f: -0.010000
ここでの ./a.out は、上記の対象 C コードからコンパイルされた実行ファイルです。
オープンソースツールチェーンとの比較
カーネルベースのオープンソースツールチェーンの大半は浮動小数点数をサポートしていません。例外として Solaris 上の DTrace と SystemTap があります。ただし、SystemTap における浮動小数点数の構文は非常に煩雑で、浮動小数点数に関するすべての処理を tapset 関数(fp_lt、fp_to_long、fp_add など)で行う必要があり、特に煩雑です。
明確なデバッグシンボルの手法
現代の最適化コンパイラは、実行時のパフォーマンスを犠牲にすることなくバイナリプログラムのデバッグを可能にするデバッグシンボル(またはデバッグ情報)を生成できます。これは本質的に、バイナリの世界におけるデバッガーのナビゲーションマップです。これらのデバッグシンボルにより、Ylang プログラム内で任意のデータ型、フィールド名、関数、グローバル/静的変数を名前で直接参照することが可能になります。Ylang は、これらの名前を Stap+、eBPF、GDB などで生成されるアナライザー内の数値にマッピングします。1
デバッグシンボル:実行時のシステムオーバーヘッドなし
C/C++ コンパイラは通常、-g(または -g3 や -ggdb などの類似オプション)をサポートしており、これにより .debug_info や .debug_line などの特別な ELF ファイルセクションにデバッグシンボルが生成されます。デバッグシンボルは DWARF 形式で保存されることが一般的です。場合によっては、コンパイラは CTF や BTF などの他のデバッグデータ形式を使用することもあります。オペレーティングシステムが実行ファイルを読み込む際、これらのデバッグシンボルはメモリにマッピングされないため、実行時のオーバーヘッドは発生しません。これらのデバッグセクションは別個のデバッグファイルとして分離することができ、本番システムには存在しない場合もあります。例えば、RPM ベースのシステムでは通常、独立したデバッグシンボルを専用の *-debuginfo RPM パッケージに集約し、APT ベースのシステムでは専用の *-dbgsym または *-dbg DEB パッケージを提供しています。
集中管理されたパッケージデータベース
当社のクローラーは、Ubuntu、Debian、CentOS、Rocky、RHEL、Fedora、Oracle、OpenSUSE、Amazon、Alpine などの主要な Linux ディストリビューションから、また MySQL や PHP などの人気のあるオープンソースソフトウェアのパッケージリポジトリから、すべての公開バイナリパッケージを継続的に収集し、OpenResty XRay のパッケージデータベースに追加しています。さらに、ユーザーのシステムに組み込みまたは独立したデバッグシンボルを持つカスタム実行バイナリがある場合、OpenResty XRay は自動的にデバッグシンボルを収集します。そして、パッケージデータベースのテナント固有のデータベースにデータをインデックス化します。セキュリティとプライバシーへの配慮から、異なるテナントは他のテナントの非公開デバッグシンボルを見ることはできません。リアルタイムで継続的に成長する集中型パッケージデータベースのおかげで、ユーザーは同じプログラムバイナリを持つすべてのマシンにデバッグシンボルをインストールする必要がありません。OpenResty XRay が特定の実行可能バイナリファイルのデバッグシンボルを一度見るだけで十分です。そして、現在のシステムにデバッグシンボルがすぐに利用できない場合でも、同じバイナリファイルを既にインデックス化した正しいバージョンのデバッグシンボルに自動的にマッピングすることができます。
パッケージデータベースはまた、デバッグシンボルデータを処理し、Ylang コンパイラ用の高速インデックスを構築します。DWARF のような複雑なデバッグデータ形式の処理はかなりコストがかかるため、形式の解析は一度だけ行うのが望ましいです。また、新しいカーネルパッケージ(ユーザーのカスタムカーネルを含む)が我々の動的トレースツールチェーンに問題がないことを確認するために、Linux カーネルのファズテストシステムを呼び出します。
パッケージデータベースは非常に大規模です!本稿執筆時点で、数百テラバイトのスペースを占有しており、さらに成長を続けています。そのため、OpenResty XRay のローカルバージョンでも、公開パッケージの取得には(暗号化された)インターネット接続を通じて当社の集中管理された読み取り専用データベースにアクセスする必要があります。ただし、ローカルバージョンの場合、パッケージデータベースのテナント部分はユーザーのコンピュータに保存されます。
本稿執筆時点で、OpenResty XRay は DWARF 形式のみをサポートしています。将来的には CTF と BTF のサポートを追加する予定です。
デバッグシンボルのファジーマッチング
時として、プログラムがデバッグシンボルなしでコンパイルされたり2、ビルドやパッケージング過程でプログラムバイナリが意図的に縮小されたり、あるいはデバッグシンボルパッケージが見つからないことがあります2。そのような場合でも、OpenResty XRayにおいて、類似した実行可能バイナリの既存のデバッグシンボルをファジーマッチングすることで、ほとんどのデバッグシンボルを自動的に構築できる可能性があります。ここでは高度な機械学習とリバースエンジニアリング技術が必要となります。まだ OpenResty XRay では利用できませんが、私たちはかなり長い間この作業に取り組んでいます。オープンソースの世界に「類似」のバイナリが存在しないユーザーのカスタムプログラムについては、それらのバイナリを -g コンパイラオプションを付けて再コンパイルし、デバッグ可能にする以外に方法はありません。
続く
以上が第3回で紹介したい内容です。第4回では、Ylang のさらなる機能と利点について説明を続けます。
著者について
章亦春(Zhang Yichun)は、オープンソースの OpenResty® プロジェクトの創始者であり、OpenResty Inc. の CEO および創業者です。
章亦春(GitHub ID: agentzh)は中国江蘇省生まれで、現在は米国ベイエリアに在住しております。彼は中国における初期のオープンソース技術と文化の提唱者およびリーダーの一人であり、Cloudflare、Yahoo!、Alibaba など、国際的に有名なハイテク企業に勤務した経験があります。「エッジコンピューティング」、「動的トレーシング」、「機械プログラミング」 の先駆者であり、22 年以上のプログラミング経験と 16 年以上のオープンソース経験を持っております。世界中で 4000 万以上のドメイン名を持つユーザーを抱えるオープンソースプロジェクトのリーダーとして、彼は OpenResty® オープンソースプロジェクトをベースに、米国シリコンバレーの中心部にハイテク企業 OpenResty Inc. を設立いたしました。同社の主力製品である OpenResty XRay動的トレーシング技術を利用した非侵襲的な障害分析および排除ツール)と OpenResty XRay(マイクロサービスおよび分散トラフィックに最適化された多機能
翻訳
英語版の原文と日本語訳版(本文)をご用意しております。読者の皆様による他の言語への翻訳版も歓迎いたします。全文翻訳で省略がなければ、採用を検討させていただきます。心より感謝申し上げます!
関連記事
OpenResty XRay Sep 20, 2023

OpenResty XRay Aug 21, 2023

OpenResty XRay Jul 6, 2023

OpenResty XRay Jun 26, 2025

OpenResty XRay Jun 26, 2025















