Ylang: eBPF、Stap+、GDB などのフレームワーク向け汎用言語(第1回、全4回)
本記事は「Ylang:eBPF、Stap+、GDB などのフレームワーク向け汎用言語」シリーズの第 1 回です。他の回は第 2 回、第 3 回、第 4 回をご覧ください。
Y または Ylang は、複数の動的トレーシングフレームワークとツールチェーン向けの汎用動的トレーシング言語です。この言語は OpenResty Inc. が開発した OpenResty XRay プラットフォームの重要な構成要素となっています。
動的トレーシングとは
動的トレーシングは、実行中のソフトウェアシステムを安全、リアルタイム、事後、効率的、かつ非侵入的な方法で分析し、トラブルシューティングのための技術の総称です。
APM のような多くの技術は非侵入的であると主張していますが、実際には対象プロセスやアプリケーションの特別な協力を必要とします。例えば、特別なモジュールやライブラリのロード、対象プロセスへの新しいコードの注入、または API 呼び出しやログファイルを通じたデータ出力が必要となります。
動的トレーシングについて、「動的トレーシング技術概論」という記事を書いたことがあります。ぜひご覧ください。
なぜ「Y」と名付けたのか
なぜこの言語を Y と名付けたのか疑問に思われるかもしれません。これは私が Cloudflare で働いていた時、CEO の Matthew Prince が付けた名前です。彼は、これが私の名前 Yichun の最初の文字であり、さらに重要なことに、「why(なぜ)」という単語と同じ発音であると説明しました。動的トレーシング言語は通常、「なぜ」で始まる複雑な質問に答えることを目的としています。当時、Ylang はまだ非常に抽象的なアイデアの段階でした。数年後、OpenResty XRay 社を設立した際、Matthew に感謝しつつ、この名前を採用することにしました。
はじめに
Hello World の例
Ylangで古典的な「hello world」の例を実装してみましょう:
$ run-y -e '_probe _oneshot { printf("Hello, world!\n"); }'
Start tracing...
Hello, world!
run-y ツールは OpenResty XRay パッケージに含まれています。
ここでの _probe キーワードは、特別なプローブポイント _oneshot に対して新しいプローブハンドラを定義し、アナライザーの起動時にトリガーされます。_oneshot プローブの実行後、アナライザは直ちに終了します。printf() 関数は標準 C 言語の printf() 関数と同等の機能を持ちます。
対象プロセスの指定
特別な _oneshot プローブは Ylangの機能を試すのに適していますが、実際の分析では(この連載の後半で、より多くの例を見ていきます)、関数プローブ、システムコールプローブ、プロセス・スケジューラー・プローブ、CPU プロファイラプローブなど、他の種類のプローブを使用します。これらの場合、PID を使用して実行中の対象プロセスを指定できます:
# 対象プロセスの PID が 5786 の場合
run-y -p 5786 my-tool.y
また、プロセスグループ ID(PGID)を指定することもできます:
# 対象プロセスグループが同じプロセス・グループ ID 14927 を持つ場合
run-y -p -14927 my-tool.y
実行中のプロセスの PID が指定されたプロセスグループ ID と一致する場合、ツールチェーンは自動的にそのプロセスから実際のプロセスグループ ID を取得します。Nginx メインプロセスを指定して Nginx プロセスグループ全体をトレースするのに便利です。メインプロセスの PID はプロセスグループ ID と同じではありません(デーモンモードが有効な場合)。
プログラムの起動時から全ライフサイクルをトレースする場合は、run-y ツールで c オプションを使用してプロセスを起動します:
run-y -c '/usr/bin/perl -e1' my-tool.y
ここでは perl コマンドの全ライフサイクルをトレースします。これにより、main 関数のエントリーポイントでのプローブなど、早期のプローブを見逃さないようにできます。
-p と -c オプションが指定されていない場合、run-y ツールはデフォルトでオペレーティングシステム全体をトレースします。
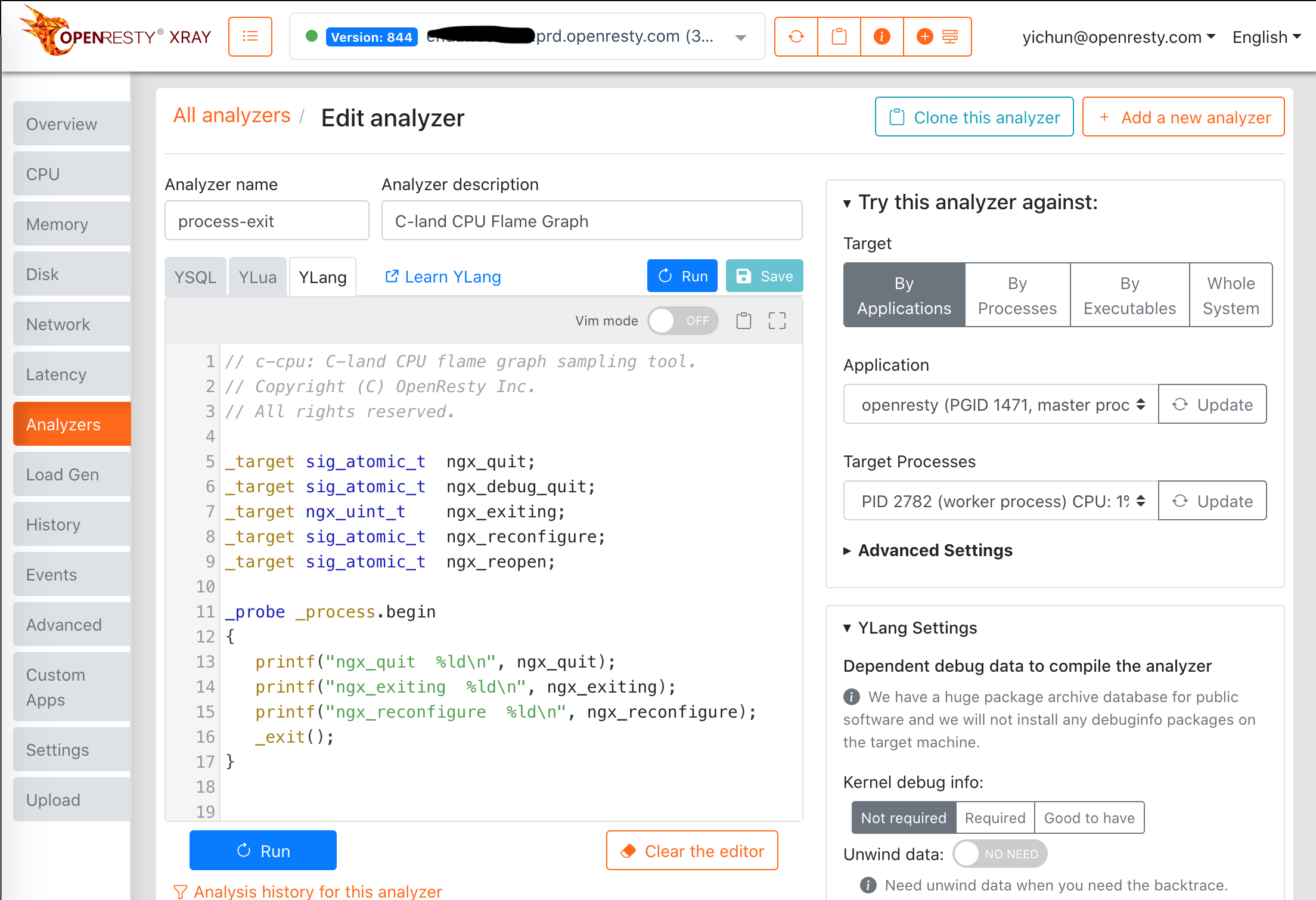
Web コンソール
OpenResty XRay の Web コンソールを使用して、Ylang プログラムやアナライザを編集・実行することもできます。以下はコンソールのスクリーンショットです。
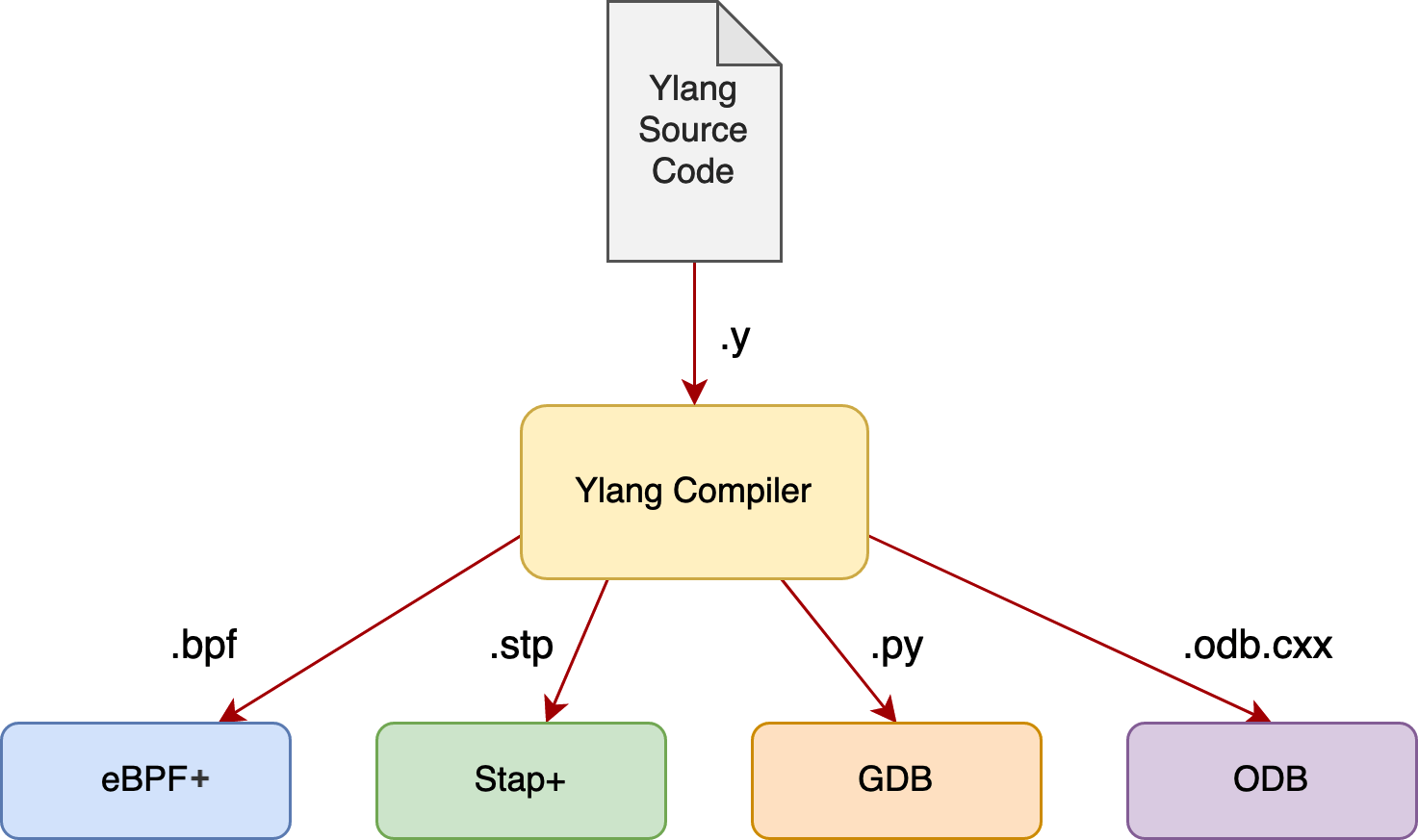
各種バックエンドとランタイム
現在、以下のバックエンドをサポートしています:
eBPF+(Linux のオープンソース eBPF 仮想マシンとツールチェーンを大幅に改良)
Stap+(Red Hat 社のオープンソース SystemTap を大幅に最適化)
GDB(GNU プロジェクトデバッガ)とその Python 拡張
ODB(OpenResty デバッガ、GDB に似ていますが、はるかに軽量)
なぜこれほど多くの異なるデバッグフレームワークが必要なのでしょうか?それは、各技術にそれぞれの長所と短所があり、異なる使用シーンに適しているためです。それぞれを詳しく見ていきましょう:
eBPF は比較的新しい技術であり、通常は新しい Linux カーネルを必要とします。しかし、SystemTap(デフォルトのカーネルランタイムを持つ)のようなフレームワークと比べて、ツールのコンパイルとロードが非常に高速です。
Stap+ は SystemTap に似ています。両者とも CentOS 7 の 3.10 カーネルを含む多くのカーネルバージョンで動作します(ただし、これは標準の 3.10 カーネルを指すものではなく、Red Hat は新しいカーネルから多くのパッチをバックポートしています)。
GDB は、core dump ファイル(クラッシュしたプロセスから)を分析できる唯一のバックエンドです。ただし、ブレークポイントを使用して関数プローブと動的トレーシングをシミュレートすることもできますが、速度が遅く、コストが高くなります。
ODB は GDB に似ていますが、GDB のような歴史的な制約がありません。これは純粋なユーザーランドトレーシングフレームワークではありますが、GDB より数桁高速です。一部の欠陥のある Intel Xeon CPU では、完全に有効なメモリアクセス要求で大量のページフォルトが発生する可能性があります。このような場合、eBPF や Stap+ のようなカーネルベースの動的トレーシングは、ページフォルトを無効にした状態で対象プロセスのメモリを読み取ることができません。したがって、ODB はこのようなチップでの唯一の選択肢となります。
私たちは、LLVM の LLDB(GDB のように Python 拡張 API を通じて)やクラッシュした Linux カーネルの core dump(kdump)ファイルを分析するためのツールなど、さらに多くのバックエンドのサポートを計画しています。
通常、OpenResty XRay は現在のユースケースと環境に適したバックエンドを自動的に選択または再選択します。ただし、ユーザーが特定のランタイムを明示的に選択することもできます。
なぜ統一されたフロントエンド言語が必要なのか
Ylang は、すべてのデバッグと動的トレーシングフレームワークに適用できる統一されたフロントエンド言語です。これにより、上記の異なるユースケースに対して大量の重複コードを書く必要がなくなります。単一の Ylang ツールを、様々な技術やフレームワークでオンライントレース、core dump ファイル分析など、多目的に即座に使用できます。Ylang コンパイラは、異なるバックエンドでセマンティクスを正確に保持することができ、これにより多大な人的リソースを節約できます。
Ylang の構文
Ylang は C 言語の大規模なサブセットを拡張し、動的トレーシングのための構文とプリミティブを提供します。C プログラマーにとって非常に使いやすいものとなっています。Ylang は、C 言語(さらには GNU C の一部)と非常に細かいレベルで真の互換性を持つことを目指しています。実際、多くの実際の C コードスニペットを編集することなく、完全に有効な Ylang コードとして使用できます。実際、MySQL や PostgreSQL のようなデータベースから、CPython、Ruby、Perl、PHP などの高級言語インタプリタやコンパイラまで、多くのオープンソースプログラムやライブラリは C 言語で書かれています。Linux カーネルも C 言語で書かれています。C++ コードも C++-to-C コンパイラを通じて C 言語に変換できます。したがって、Chromium、Qt、JVM、NodeJS などの C++ オープンソースプロジェクトも、新しい Ylang アナライザやツールのコードソースとなり得ます。
なぜ対象ソフトウェアと同じ言語を使用することがこれほど重要なのでしょうか?それは、対象アプリケーション用の新しいアナライザを作成する際、最も面倒で労力を要する部分が対象のデータ構造を扱うことだからです。対象アプリケーション自体がこれらのデータ構造を使用する必要があるため、必要な情報を収集するために成熟したコードを直接借用するのが最も自然な方法です。単純なコピー&ペーストにより、新しい動的トレーシングツールやアナライザの作成コストを大幅に削減できます。
C スタイルの Ylang に加えて、OpenResty XRay は Ylang の他の言語向けコンパイラも提供しています。例えば、Lua 構文の YLua や SQL 構文の YSql があります。これらの言語については、後続の記事で紹介します。また、Python、Ruby、Java、Rust、Go などの言語の Y バリアントもサポートする予定です。
他のツールチェーンで使用される言語
Stap/D/Bpftrace: C に似ているが C ではない
DTrace、SystemTap、Bpftrace(eBPF 向け)などの他のオープンソースフレームワークは、独自のスクリプト言語を導入しています。残念ながら、これらの言語は C 言語に見えるだけで、C 言語との真の互換性を考慮していません。そのため、対象アプリケーションの C コードを単純にコピー&ペーストすることはできません。これらのフレームワークのスクリプト言語にコードを移植するのは非常に時間と労力がかかります。ツールのロジックが複雑な場合、移植されたツールの正確性をテストしてデバッグするのも容易ではありません。
本物の C プログラマーにとっては、C らしく見えないかもしれません。SystemTap のスクリプト言語を例に見てみましょう。以下の Ylang コードスニペットを見てください:
_target long *my_var;
int get_val(void) {
return *(int *) my_var;
}
特別な _target キーワード以外は、このスニペットは完全に C プログラムのように見えます。_target キーワードは Ylang が導入した拡張機能です。このキーワードは、宣言されたシンボルが対象プロセス(または tracee 空間)からのものであることを示します。このコードを SystemTap スクリプトに変換すると、次のようになります:
function get_val() {
return @cast(@var("my_var", "/path/to/target/exe/file"), "int", "/path/to/target/exe/file")[0];
}
これは全く異なって見えており、より冗長です。実行可能ファイルのパスをコードにハードコードするか、マクロを通じて渡す必要があります。
これらのスクリプト言語の最も重要な問題点は、C スタイルの型システムが欠如していることです。通常、符号付き long int 型のみを使用して整数を表現できます。C 言語の整数型変換や算術演算のセマンティクスをすべて自分でシミュレートする必要があり、これは非常に面倒で間違いやすいものです。
GitHub の公開リポジトリで、複雑な SystemTap スクリプト、openresty-systemtap-toolkit、stapxx などの手書きの実例を見ることができます。このようなスクリプト言語は通常あまり役に立たず、より有用なコマンドラインツールにするために Perl wrapper を書く必要があります。Python や Bash などの他の強力なスクリプト言語でこのような wrapper を書くことを好む人もいます。
しかし、Ylang を使用すれば、ユーザーは C 言語と互換性のある言語を1つだけ使用すればよく、他のスクリプト言語の複雑な wrapper は必要ありません。
eBPF: C だが C より難しい
公式の eBPF ツールチェーン(BCC を含む)は通常、LLVM と Clang を通じて自然な C 言語を使用します。残念ながら、この C 言語にも多くの深刻な制限があります。以下に例を挙げます:
- ユーザー定義関数は最大 5 つの引数しか受け付けません1。
- Linux カーネル eBPF 検証器の静的コード解析により、フロー制御文に多くの制限があります。この検証器は大規模な eBPF プログラムに大きな CPU オーバーヘッドをもたらします。後方ジャンプと通常のループは通常無効化されています。
- 関数の戻り値と引数を通じて複合型(struct や union など)の値を渡すことはできません2。
.data、.rodata、.bssなどのデータセグメント間のデータ参照の再配置は現在サポートされていません3。- 対象プロセスで定義された型に対する組み込みサポートがないか、非常に限られています。そのため、ユーザーは通常すべての型を手動で宣言する必要があります。
- 組み込みの VMA トラッカー4サポートがないため、ユーザーは仮想メモリアドレスを自分で計算する必要があり、これは非常に面倒で間違いやすいものです。
- 組み込みのスタックアンワインダーは、対象プロセスの unwinding tables や DWARF データを使用せず、対象プロセスのコンパイル時にフレームポインタレジスタを無効にすることに依存しています。
- BPF Map とスタックベースの自動変数以外に、ランタイムには組み込みのメモリ割り当てと管理メカニズムがありません。最も一般的な C 文字列を扱うのも非常に困難です。
- コンパイラツールチェーンと BPF 命令セットの両方で、符号付き除算演算のサポートがありません5。
- 浮動小数点数をサポートしていません6。
これ以外にも多くの制限があります。私たちはよく冗談で、多くの人がカーネル C コードを書くのは非常に難しいと考えているが、実際には少し複雑な eBPF C コードを書くのはカーネル C コードを書くよりもはるかに難しいと言っています。幸いなことに、Ylang が使用する eBPF+ 実装は、上記の問題のほとんどを解決しており、Ylang コンパイラはこのような複雑な eBPF C コードを自動的に書くことができます。面倒な詳細を考慮することなく、自然でクリーンな C コードを書くことができます。
それでも、標準の eBPF ツールチェーンは、Python や C などの言語で書かれた独立したユーザーランドプログラム(ほとんどの人が Python を使用)を必要とします。これは SystemTap のスクリプト言語で書かれたツールの shell wrapper よりも面倒です。Ylang コンパイラはこのようなユーザーランドプログラムも自動生成できます(Ylang はこのようなプログラムに最適化された C コードを生成できます。Python は処理が重く遅いためです)。
GDB/LLDB: C に全く似ていない
C 言語の構文とは全く異なる言語を使用して C/C++ アプリケーションを分析するツールを書くのは、さらに困難です。例えば GDB と LLDB では、GDB は新しい拡張を書くために Python と Scheme 言語を提供しています。一方、LLVM は Python を提供しています。Python を使用して Python アプリケーションをトレースするのは自然に感じるかもしれませんが、そうではありません!このような GDB Python コードは常に C のような低レベル言語で書かれたものを分析するために使用されます!これにより、単純な C のロジックでさえ、恐ろしい Python コードになってしまいます。例えば、以下のシンプルな C 文を見てみましょう:
int a = *(int *) my_var;
ここで my_var は対象プロセスの変数です。これを GDB Python コードスニペットに変換すると、次のようになります:
sym_my_var = gdb.lookup_global_symbol("my_var")
if sym_my_var is None:
sym_my_var, _ = gdb.lookup_symbol("my_var")
a = sym_my_var.value().cast(gdb.lookup_type("int").pointer()).dereference()
Ylang では、前者のコード形式を書き、対象変数 my_var を次のように宣言できます:
_target long *my_var;
_target キーワードは Ylang の新しい拡張で、対象ソフトウェアのシンボルを示します。
GDB Python では、複雑さが蓄積されると状況は急速に悪化します。GDB の手書き Python スクリプトを例として見てください。これは悪夢のような複雑さです。
幸いなことに、Ylang コンパイラは上記の冗長で遅い Python コードを生成する必要はありません。面倒な gdb.Value オブジェクトを回避し、より簡潔なコードを生成できます。これには以下の利点があります:
- 生成された Python コードは実行時に明らかに高速です(時には数倍速くなります)。
- 生成されたコードはより簡潔なため、サイズも大幅に小さくなります。
- 生成されたコードは対象環境に DWARF データが存在することをもはや要求しません(したがって、DWARF なしと呼ばれます)。
それでも、Ylang コンパイラは、ユーザーが 2 つの比較検証用として、従来の低速な形式のコードを生成することもできます。
未完待続
この記事はすでに長くなっています。第 2 回からは、Ylang の機能と例により焦点を当てていきます。
著者について
章亦春(Zhang Yichun)は、オープンソースの OpenResty® プロジェクトの創始者であり、OpenResty Inc. の CEO および創業者です。
章亦春(GitHub ID: agentzh)は中国江蘇省生まれで、現在は米国ベイエリアに在住しております。彼は中国における初期のオープンソース技術と文化の提唱者およびリーダーの一人であり、Cloudflare、Yahoo!、Alibaba など、国際的に有名なハイテク企業に勤務した経験があります。「エッジコンピューティング」、「動的トレーシング」、「機械プログラミング」 の先駆者であり、22 年以上のプログラミング経験と 16 年以上のオープンソース経験を持っております。世界中で 4000 万以上のドメイン名を持つユーザーを抱えるオープンソースプロジェクトのリーダーとして、彼は OpenResty® オープンソースプロジェクトをベースに、米国シリコンバレーの中心部にハイテク企業 OpenResty Inc. を設立いたしました。同社の主力製品である OpenResty XRay動的トレーシング技術を利用した非侵襲的な障害分析および排除ツール)と OpenResty XRay(マイクロサービスおよび分散トラフィックに最適化された多機能
翻訳
英語版の原文と日本語訳版(本文)をご用意しております。読者の皆様による他の言語への翻訳版も歓迎いたします。全文翻訳で省略がなければ、採用を検討させていただきます。心より感謝申し上げます!
このような再配置の欠如は、実行時に NULL ポインタの deference を引き起こす可能性があり、これは kernel panic を引き起こす可能性があります。 ↩︎
eBPF C 開発者は Clang コンパイラのエラー「functions with VarArgs or StructRet are not supported」によく遭遇します。 ↩︎
VMA トラッカーは、対象プロセスの相対アドレスを絶対仮想メモリアドレスにマッピングし、その逆も行います。 ↩︎
eBPF の C 言語開発者は、「Unsupport signed division for DAG」や「error in backend: Cannot select: 0x55ba75efac30: i64 = sdiv」などの Clang コンパイラのエラーによく遭遇します。 ↩︎
多くの動的トレーシングフレームワークは浮動小数点数をサポートしていません。例外は SystemTap(最近この機能を追加)、GDB Python、Solaris 上の DTrace(他の OS 上の DTrace ポートはまだこの機能を欠いています)のみです。 ↩︎
関連記事
OpenResty XRay Sep 20, 2023

OpenResty XRay Aug 22, 2023

OpenResty XRay Aug 21, 2023

OpenResty XRay Jun 26, 2025

OpenResty XRay Jun 26, 2025


















