OpenResty の隠れたメモリリークを無停止で特定する手法(Zero Downtime)
皆様の生産環境でも、このような問題に直面されたことはありませんか? Nginx または OpenResty をベースとしたコアゲートウェイにおいて、明らかなトラフィック異常がないにもかかわらず、メモリ使用量がまるで魔法にかかったかのように、ゆっくりと着実に増加し続ける現象です。
数日もすれば、単一のワーカープロセスのメモリは数百メガバイトから 1G 以上に達し、システム OOM (Out of Memory) のアラートがいつ発生してもおかしくない状況となります。最も厄介な解決策は、再起動という最終手段しか残されていないように思えますが、これは基幹業務においては「毒を飲んで渇きを癒す」ようなもので、一時的に問題を緩和することはできても、根本的な解決にはなりません。何よりも重要なのは、次にいつ危機が訪れるか全く予測できないことです。これは、最近弊社で対応した実際のケースです。高並行処理を行う API ゲートウェイが、まさにこの困難に直面していました。本記事では、サービスを再起動せず、ビジネスに影響を与えることなく、 Nginx 内部に潜むこのメモリリーク問題をいかにして正確に特定し、解決したかをご紹介します。
この難局を打開する鍵は、「どのようなツールを使うべきか」ではなく、まず明確で検証可能な分析経路を確立することにあります。当方では、トップダウンで段階的に焦点を絞り込んでいく方法論を採用しています。これは速度を追求するためではなく、本番環境において確実性を得るためです。
本番環境におけるメモリリークの徹底解剖
Step 1:システム層の現象確認 → アロケータの特定
まず、システム層から着手し、メモリ増加の真の実態を確認します。OpenResty XRay のガイド付き分析機能を実行することで、高メモリ問題を自動分析します。自動分析レポートの結果から明確に示されているのは、Nginx worker プロセス のメモリ使用量がすでに 1GB を超え、さらに継続的に増加していることです。
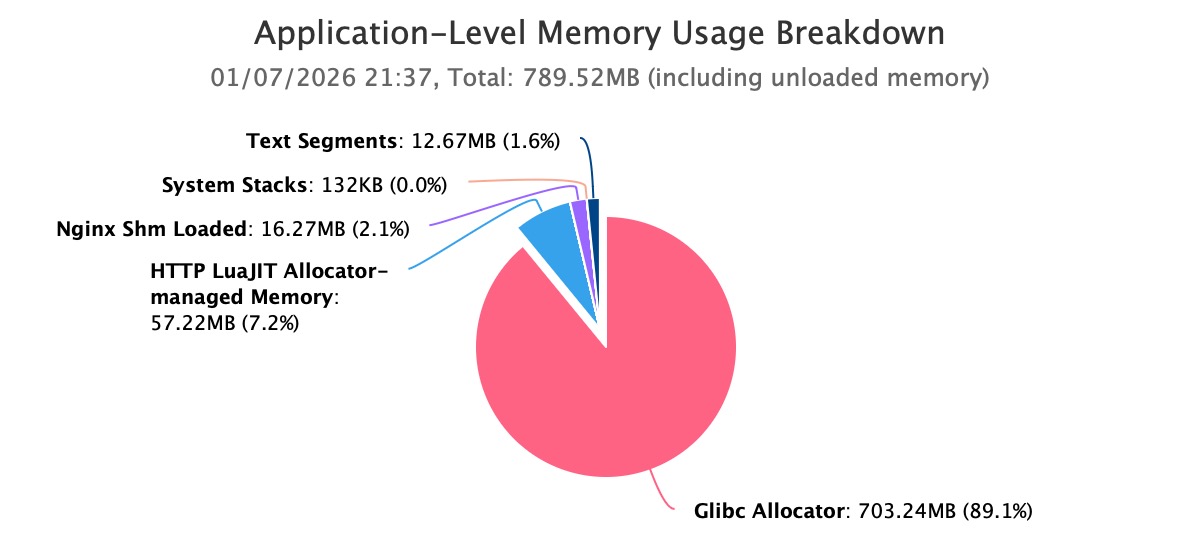
詳細な分析により、このメモリ消費量の大部分が Glibc Allocator によって占有されていることが判明しました。このステップにより、カーネル キャッシュ、ファイル システム、またはその他の周辺コンポーネントの問題が直接的に排除され、焦点はアプリケーションプロセス自身のメモリ割り当て動作にしっかりと絞り込まれます。
この結論は極めて重要です。これにより、カーネルモード リーク、ファイル キャッシュ、または外部プロセス干渉といった可能性が排除され、問題の範囲がアプリケーション自身のメモリ割り当て動作に明確に限定されます。
ステップ 2:アロケータの特定 → Nginx メモリプールの詳細分析
メモリが主に Glibc によって管理され、プロセスが Nginx であることから、これらのメモリは Nginx のメモリプールシステムによって利用されている可能性が最も高いと考えられます。ここで本当に難しいのは、Glibc が確保したメモリが、具体的にどの Nginx メモリプールによって消費されているのかという点です。
Nginx メモリプールの詳細な分析を行った結果、すぐに異常が集中している箇所を発見しました。
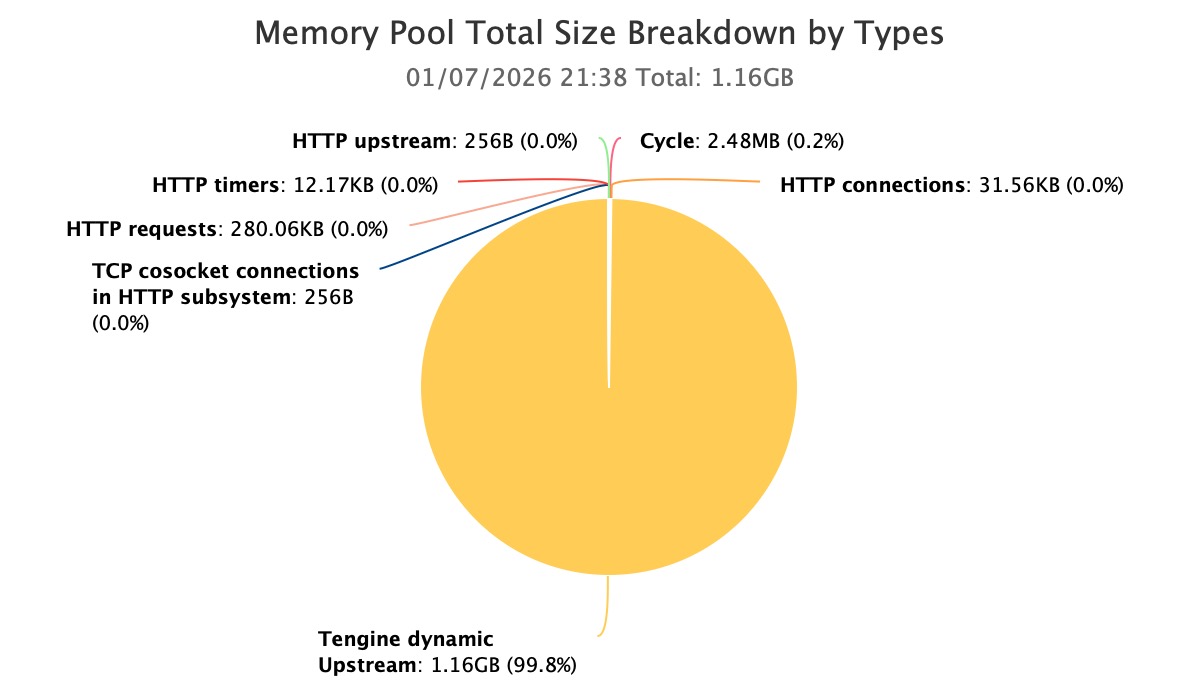
現在のプロセスにおける主要なメモリ消費は、Tengine dynamic upstream モジュールによって作成された Nginx メモリプールに起因しています。
これにより、問題は「プロセスレベルでのメモリ制御不能」という広範な状態から、「特定のメモリプールの異常な増加」という具体的な事象へと絞り込まれました。
Step 3:Nginx メモリプールに焦点を当てる → モジュールレベルでの問題特定
問題が dynamic upstream 関連のメモリプールに集中していることを確認した後、Glibcアロケータ層をさらに深掘りし、再度 OpenResty XRay を実行してメモリブロックのサイズ分布を分析しました。
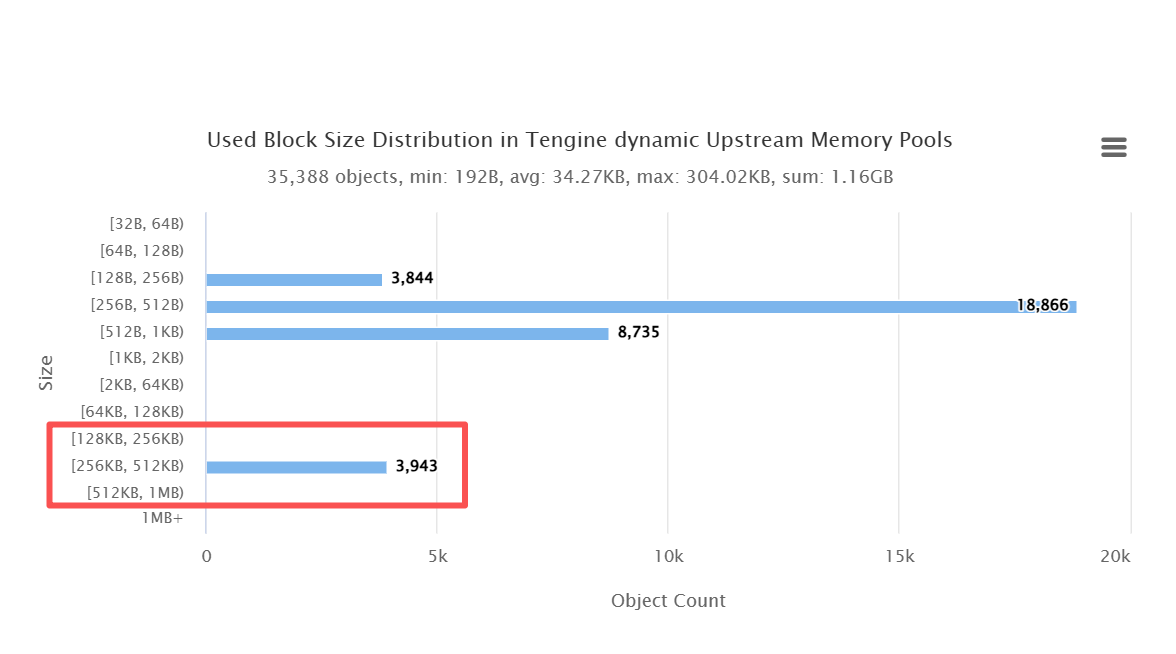
その結果は非常に明確でした。256KB~512KB の範囲に 2240 個ものメモリブロックが存在し、その数は通常の動作時の分布パターンから著しく逸脱していました。このサイズのメモリが大量に集中していることは、これらが短寿命オブジェクトではなく、長期的に保持され、かつ解放されていない状態にあることを示唆しています。
この発見は、「メモリリーク」の強力かつ定量的な証拠となり、もはや経験的な判断に留まるものではありません。
ステップ 4:モジュールレベルでの特定 → C コード呼び出し経路の追跡
異常なメモリー プールを特定し、異常なメモリー ブロックの形態も確認しました。最後のステップは、最も重要な問いに答えることです。すなわち、これらのメモリーは一体どのコード パスで割り当てられ、最終的に解放される機会を逸してしまったのか、という問いです。
c-memory-leak-fgraph ツールを使用することで、メモリー プールの割り当て動作を C コードレベルの関数呼び出し関係に完全にマッピングします。その結果、明確で完全なメモリー リークの呼び出し経路が浮かび上がります。これはメモリー割り当て点から始まり、モジュール内のロジック全体を横断し、解放されるべきタイミングまで続きます。
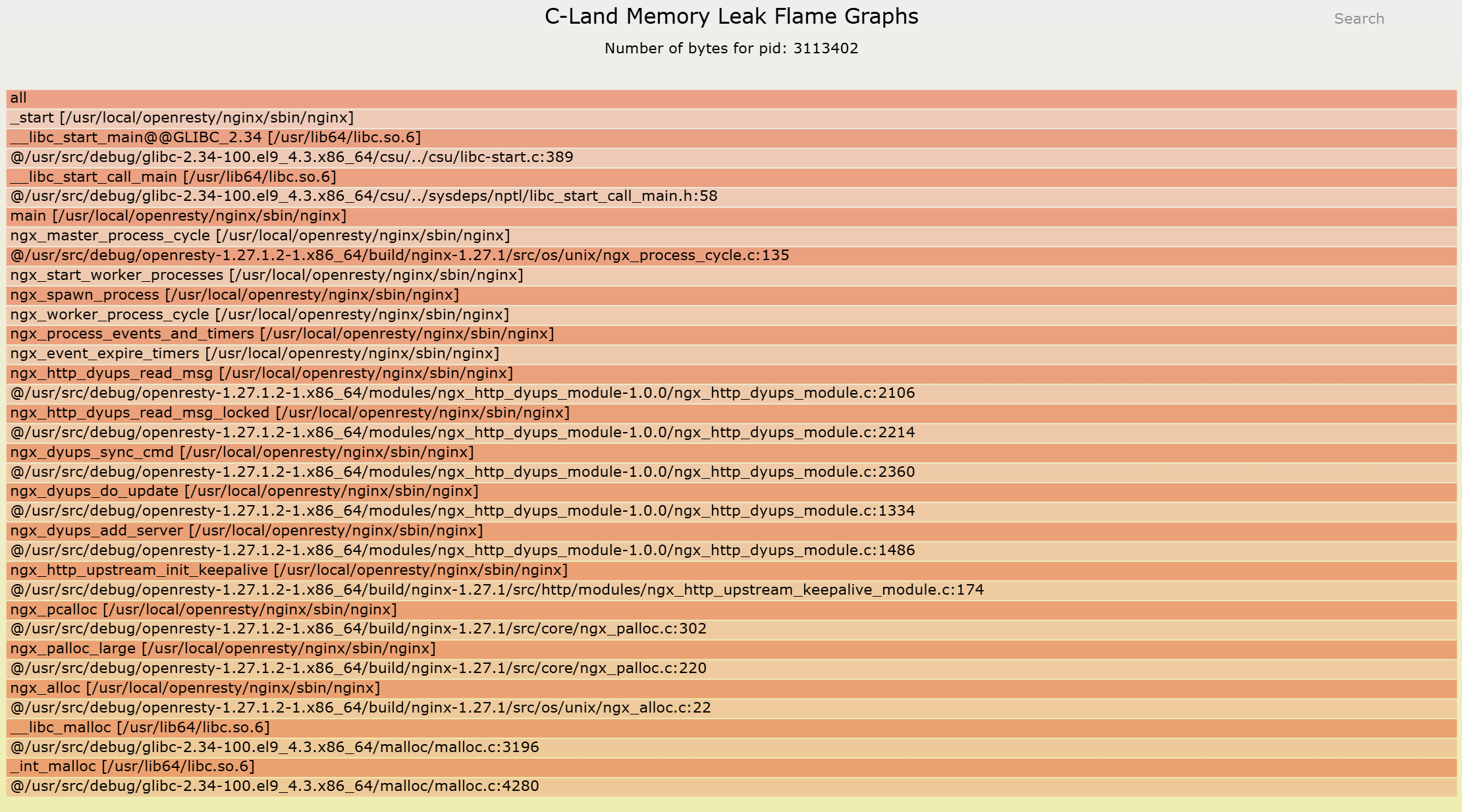
この瞬間、問題は「どこにあるかもしれない」という推測ではなく、「まさにここで発生している」という確信に変わります。
再起動せず、本番トラフィックに影響を与えないという前提のもとで、Nginx メモリー プール内部に深く埋もれたリーク問題を、完全かつ正確に追跡可能な C コード呼び出し経路として再現することに成功しました。推測に頼ることも、再起動による一時的な解決に頼ることもなく、検証可能で修正可能な確実な証拠を掴んだのです。
この分析経路自体は複雑ではありませんが、厳密な前提条件があります。それは、本番環境で Glibc アロケーター、Nginx メモリー プール、そして C コードという 3 層の境界を安全に越えて観測し、関連付けることができる必要がある、という点です。
まさにこのような現実的で厳しいシナリオにおいて、OpenResty XRay の専門的な性能エンジニアリング能力の価値が、真に発揮されるのです。
なぜ、このような問題は解決が極めて困難なのか?
多くのチームがこのような問題に直面した際、しばしば対応に窮します。これは技術力不足によるものではなく、問題の複雑さが一般的なツールや知識の範疇を超えているためです。
1. Nginx メモリプール:ブラックボックス
一般的に馴染み深い malloc/free とは異なり、Nginx はパフォーマンス向上のため、独自のメモリプールを設計しています。メモリの確保と解放は Nginx によって管理されるため、valgrind のような従来のメモリリーク検出ツールは、ほぼ完全に機能しなくなります。これらのツールは Nginx メモリプールのライフサイクルを理解できず、本番環境で valgrind を強制的に使用することは、極めて危険な行為であり、壊滅的なパフォーマンス低下を招くでしょう。
2. Glibc アロケータ:問題の潜伏先
さらに詳細に見ると、Nginx メモリプール自体も Glibc の malloc の上に構築されています。リークが発生した場合、top や pmap から確認できるのは、Glibc アロケータが保持するメモリ総量が増加していることだけです。今回のケースでは、問題は大量の 256KB~512KB のメモリブロックの中に巧妙に隠されており、外部からこれらのメモリブロックを Nginx 内部の具体的なオブジェクトと関連付けることは全くできません。
3. 動的モジュールの複雑性
この事例におけるサービスは、Tengine の動的アップストリーム(dynamic upstream)モジュールを利用していました。この種のモジュールの特徴は、その内部オブジェクトが複雑かつ長寿命の管理ロジックを有していることです。これらのロジックが Nginx のイベント駆動、非同期 I/O モデルと結合すると、異なるコードの実行経路やタイミングにおけるメモリの割り当てと解放の追跡は、その難易度が指数関数的に増大します。
これら三つの大きな課題は、エンジニアを「誤った試み」のサイクルに陥らせました。カーネルパラメータ drop_caches を調整しても、それは対症療法に過ぎません。worker_rlimit を増やしても、遅かれ早かれクラッシュするでしょう。最終的に残されたのは、SRE チームを夜通し悩ませる systemctl restart nginx という手段だけでした。
このような状況下で、エンジニアの間では、明確でありながらも無力感のある共通認識が形成されます。それは、「問題があることは分かっているが、その実態が見えない」というものです。メモリが増加していることを知らないわけではなく、それがなぜ増加しているのか、そしてどこに手を打つべきか、全く見当がつかないのです。
「運任せ」から「予測可能」なシステムへ
このバグを特定し修正することの価値は、単にメモリを節約するだけにとどまりません。それは、システムが「運任せに稼働する」状態から、「健全で予測可能」なシステムへと進化することを意味します。これまでの経験から、このような修正は通常、以下のような顕著な定量的な効果をもたらします。
メモリと可用性の改善:
- メモリ使用量を 70-90% 削減: worker プロセスのメモリ使用量が 1G 超から 200-300MB レベルに安定しました。
- OOM クラッシュの根絶:サービス可用性が 99.5% (定期的な再起動に依存)から 99.9% + の安定稼働状態に向上しました。
パフォーマンスとコストの最適化:
- 運用コストを 50% + 削減:アラートの多発が解消され、 SRE チームはメモリ問題に対する無駄な調査や再起動作業に時間を費やす必要がなくなりました。
- ハードウェアコストの最適化:メモリ使用量の低減により、将来的にサーバーメモリ構成費用を 30-50% 削減できる見込みです。
その核心的な価値は、毎月数万円規模の事業損失を引き起こす可能性があった時限爆弾を、完全に解除した点にあります。
パフォーマンス問題が「ツール」の域を超える時
この事例は、ある見解を明確に示しています。システムの複雑さが一定の閾値を超えると、パフォーマンス問題はもはや単なる「ツールで解決できる問題」ではなく、「方法論と豊富な経験」が問われる総合的な課題となるのです。
従来のツールが通用しなくなるのは、それらがより単純で汎用的な問題を解決するために設計されているからです。しかし、Nginx のメモリプールと Glibc のアロケータが複雑に絡み合うような状況に直面した場合、必要となるのは OpenResty XRay のようにシステムの「深部」まで入り込む洞察力と、サービスを中断することなく診断を完遂する実践的な経験です。
これは、たとえ技術力の高いチームであっても、特定の困難なパフォーマンスボトルネックに直面した際に、なぜ専門のパフォーマンスエンジニアの支援が必要となるのかを説明しています。なぜなら、彼らがもたらすのは単なるツールではなく、複雑な問題を体系化し、可視化できるエンジニアリングにおける方法論だからです。
OpenResty XRay について
OpenResty XRay は動的トレーシング製品であり、実行中のアプリケーションを自動的に分析して、パフォーマンスの問題、動作の問題、セキュリティの脆弱性を解決し、実行可能な提案を提供いたします。基盤となる実装において、OpenResty XRay は弊社の Y 言語によって駆動され、Stap+、eBPF+、GDB、ODB など、様々な環境下で複数の異なるランタイムをサポートしております。
著者について
章亦春(Zhang Yichun)は、オープンソースの OpenResty® プロジェクトの創始者であり、OpenResty Inc. の CEO および創業者です。
章亦春(GitHub ID: agentzh)は中国江蘇省生まれで、現在は米国ベイエリアに在住しております。彼は中国における初期のオープンソース技術と文化の提唱者およびリーダーの一人であり、Cloudflare、Yahoo!、Alibaba など、国際的に有名なハイテク企業に勤務した経験があります。「エッジコンピューティング」、「動的トレーシング」、「機械プログラミング」 の先駆者であり、22 年以上のプログラミング経験と 16 年以上のオープンソース経験を持っております。世界中で 4000 万以上のドメイン名を持つユーザーを抱えるオープンソースプロジェクトのリーダーとして、彼は OpenResty® オープンソースプロジェクトをベースに、米国シリコンバレーの中心部にハイテク企業 OpenResty Inc. を設立いたしました。同社の主力製品である OpenResty XRay動的トレーシング技術を利用した非侵襲的な障害分析および排除ツール)と OpenResty XRay(マイクロサービスおよび分散トラフィックに最適化された多機能
翻訳
英語版の原文と日本語訳版(本文)をご用意しております。読者の皆様による他の言語への翻訳版も歓迎いたします。全文翻訳で省略がなければ、採用を検討させていただきます。心より感謝申し上げます!
関連記事
OpenResty XRay Jul 16, 2025

OpenResty XRay Dec 23, 2025

OpenResty XRay Sep 1, 2025

OpenResty XRay Jul 8, 2025

OpenResty XRay Jul 15, 2023















