GSLB 設計手記:トラフィック制御を「アプリケーション層」から再考する
インターネット アーキテクチャは今日に至るまで進化を遂げ、アプリケーション層の複雑さはすでに指数関数的に増大しています。GSLB(グローバルロードバランシング)は、DNS による動的解決を通じてユーザーリクエストを最適なノードに割り当てることで、大規模サービスにおいてユーザー体験を確保するための重要な技術です。しかし、最上位レイヤーに位置する広域負荷分散(GSLB)のコア ロジックは、いまだ 10 年前のままに留まっているようです。
従来の GSLB は、「ネットワークが接続可能か」や「距離が近いか」を重視しており、これは静的ウェブページが主流だった時代には十分だったかもしれません。しかし、動的コンテンツが中心となり、計算能力に大きな差がある今日において、ネットワーク層の ICMP や TCP ハンドシェイクのみに依存してノードの処理能力を判断することは、まさに隔靴掻痒(かっかそうよう)と言わざるを得ません。このようなアーキテクチャ層の乖離は、突発的なトラフィックに直面した際、手動による介入、すなわち「属人的な運用」へと退化せざるを得ない状況を生み出しています。真の解決策は、調度の判断をビジネス本来の姿に立ち返らせることにあります。すなわち、マシン負荷やリクエスト速度といったカスタムビジネス指標に基づき、トラフィックを異なるマシン、さらには異なるクラスターへと動的に再分配することです。
なぜ GSLB の「課題」は、いまだに解消されていないのか
ここから、典型的な運用シナリオが浮かび上がります。監視パネル上で、あるエッジノードの CPU 負荷が異常に急上昇し、その上昇率は予想をはるかに超えていました。標準的な運用手順(SOP)に従い、担当者は DNS コンソールにログインし、当該ノードのルーティングウェイトを 80 から 60 に引き下げました。しかし、TTL が設定されているため、トラフィック曲線がゆっくりと下降し始めるまでには十数分 を要し、この遅延した対応が原因で、別のノードが過剰な溢れ出したトラフィックを受け止めきれずにアラートを発する事態となりました。担当者は二次的な修正対応を余儀なくされますが、修正のたびに、この長いフィードバックループの中で、さらに十数分間 の待機と調整を強いられることになります。
このような繰り返しの微調整と待機を経て、システムはようやく一時的に安定しました。しかし、この一連のプロセスでは、常に監視に目を光らせる必要があるだけでなく、DNS の伝播遅延を我慢し、不安を抱えながら各調整が反映されるのを待つ必要がありました。トラフィックは切り替わり、サービスも持ちこたえましたが、このような手動での試行錯誤を繰り返して得られる安定は、プロセスが煩雑である上にリスクも決して低くなく、常に綱渡りをしているような感覚を覚えます。問題は解決したものの、その解決方法は決して理想的とは言えません。
トラフィック制御の「痛点」は本当に「設定の複雑さ」なのか
このような問題は、「経験不足」や「事前の対策不足」に起因すると考えられがちです。しかし、エンジニアとしては、ツールそのものを見直すべきではないでしょうか。既存のトラフィック制御ツールは、このような連続的に変化する状況に本当に適しているのでしょうか?
私たちが普段利用する代表的なトラフィック制御ツールをいくつか挙げてみましょう。DNS 重み付け、ヘルスチェック、さらにはシンプルな GSLB などです。これらにはいくつかの共通する特徴があります。
- 離散的:重み付けの値は、例えば 80 や 70 といった静的な設定です。「ノードの負荷が 75% に達したら、重み付けを 80 から 75 へ滑らかに下げる」といった、動的で連続的な応答戦略を表現することはできません。
- 二値的:ヘルスチェックの結果は通常、「正常」か「異常」のいずれかしかありません。ノードはオンラインかオフラインかのどちらかであり、「ノードはオンラインだが、応答遅延がすでに急上昇している」といった「準正常」な状態を把握することはできません。
- 急激な変化:ヘルスチェックの失敗であれ、手動で重み付けを 0 に設定することであれ、トラフィックの切り替えは断崖式に行われます。このような急激な変化自体が、ユーザーエクスペリエンスや他のノードに大きな影響を与える可能性があります。
これらのツールが設計された当初の核心的な仮定は、「サーバーの状態は比較的安定しており、変化は低頻度である」というものでした。しかし今日では、ビジネスの弾力的なスケーリング、トラフィックの瞬間的なスパイク、サービスの優雅なダウングレードなどにより、システムの状態は連続的に変化するプロセスとなっています。私たちは、「スイッチ式」の離散的なツールを使って、状態が連続的に変化するシステムを管理しようとしています。このようなツールと状況のミスマッチこそが、運用プロセスにおける「不確実性」の根源なのです。
「全体最適」と「障害影響の最小化」をどう両立するか
より理想的なトラフィック制御ツールには、以下の3つの基本的かつ重要な要件があります。
- 段階的なトラフィック調整(平滑遷移):特定のノードの負荷が上昇し、健全ではない状態(準正常状態)を示し始めた際、システムは自動的に、段階的にそのノードへのトラフィックを削減すべきです。これは、手動介入を待ったり、ノードが完全に利用不能になってから一気に遮断するような対応とは異なります。
- 自動遮断(サーキットブレーカー):ノードの負荷が安全しきい値を超え、これ以上リクエストを処理できないと判断された場合、システムは自動的かつ迅速にそのノードを隔離し、新規トラフィックの受け入れを停止することで、ノード自体とサービス全体の安定性を保護します。
- 可観測性と追跡可能性:すべてのトラフィック制御に関する決定は、自動か手動かにかかわらず、明確に記録されている必要があります。これにより、事後監査が可能となり、任意の時点でシステムがどのような処理を行い、その決定の根拠は何だったのかをエンジニアが把握できるようになります。
これら 3 つの要件は、高度な技術指標というよりも、エンジニアが運用ツールに求める本質的なニーズに近いものです。それは、反復的でリスクの高い判断を自動化しつつ、最終的な制御権と状況を把握する権利をエンジニアに委ねることを意味します。
TCP レベルのプローブでは「処理能力」を測れない理由
従来の GSLB ヘルスチェックは、主に Ping やポートプローブに依存しており、ノードが「稼働しているか停止しているか」を判断できるに過ぎず、「サービス品質」を評価することはできませんでした。
OpenResty Edge は、ヘルスチェックの視点をネットワーク層からアプリケーション層へと拡張し、ユーザーが自社のビジネス特性に応じて、調度の意思決定に用いる指標をカスタマイズできるようにしています。以下はその代表的な例です。
- requests per second:アプリケーションが1秒あたりに処理するリクエスト数。
- active connections:現在のアクティブな接続数。
- システム分単位の平均負荷。
これらのアプリケーション層指標の意義は、ノードの「生死」だけでなく、その「サービス能力」と「正常性」に着目している点にあります。スケジューリングシステムが取得する情報が実際のビジネス負荷により即している場合、その意思決定も自然とより正確になります。従来のソリューションを否定するものではありませんが、現在の複雑なビジネスシナリオにおいては、ネットワーク層の情報だけでは確かに不十分になっているのです。
受動的な応答から「フィードバックループに基づく」動的な状況把握へ
OpenResty Edge の GSLB 機能は、まさに上記のシナリオを念頭に置いて設計されています。これは、より実際の負荷変動に即した方法でトラフィックのスケジューリングを行います。マシン負荷やリクエスト速度といったカスタムビジネス指標に基づき、トラフィックを異なるマシン、さらには異なるクラスターへと動的に再分配する——単に「接続が可能か否か」を見るのではなく、「サービスが負荷に耐え、処理能力を維持できるか」を重視し、その判断に基づいて能動的にトラフィックの行き先を調整します。
「動的ウォーターマーク」による耐障害性ロジック
システムが「不健全な状態」に陥ることを防ぐため、OpenResty Edge GSLB は、従来の単一しきい値に代わり、「高低水位(Watermark)」モデルを導入しました。
- 低水位:ノードの特定の指標(CPU 負荷など)が低水位を超過した場合でも、システムは直ちにそのノードをサービスから切り離すことはありません。代わりに、トラフィックの重みを段階的に引き下げ始めます。これにより、バッファ領域が提供され、トラフィックを滑らかかつ漸進的に削減することで、ノードに負荷を軽減し、自己回復を促す機会を与えます。
- 高水位:指標がさらに悪化し、高水位に達した場合、システムはサーキットブレーカー を発動します。この時点で、GSLB はそのノードへの新規トラフィックの分配を停止し、そのトラフィックを同一クラスター内の他の健全なノードへ自動的に移行させます。さらに必要に応じて、クラスターをまたいで異地のバックアップクラスターへのトラフィック調度も行います。これにより、ノードが完全に過負荷に陥るのを防ぎ、サービス全体の継続的な可用性を保護します。
この設計の核心は、ノード間でトラフィックが急激かつ突発的に切り替わるのを避けることにあります。これは、経験豊富なエンジニアの意思決定プロセスを模倣しています。すなわち、まず穏やかに機能を縮退させ(ダウングレード)、次に状況に応じて果断にサーキットブレーカーを発動するという流れです。
意思決定の可視化と説明責任
制御システムにおいて、自動化の度合いが高まるほど、「状態の透明性」に対する要求は厳しくなります。GSLB のようなトラフィックの入り口となる決定システムでは、運用担当者がログやパネルからその決定根拠を遡って確認できない場合、その自動化は本質的に制御不能なリスクをはらんでいます。
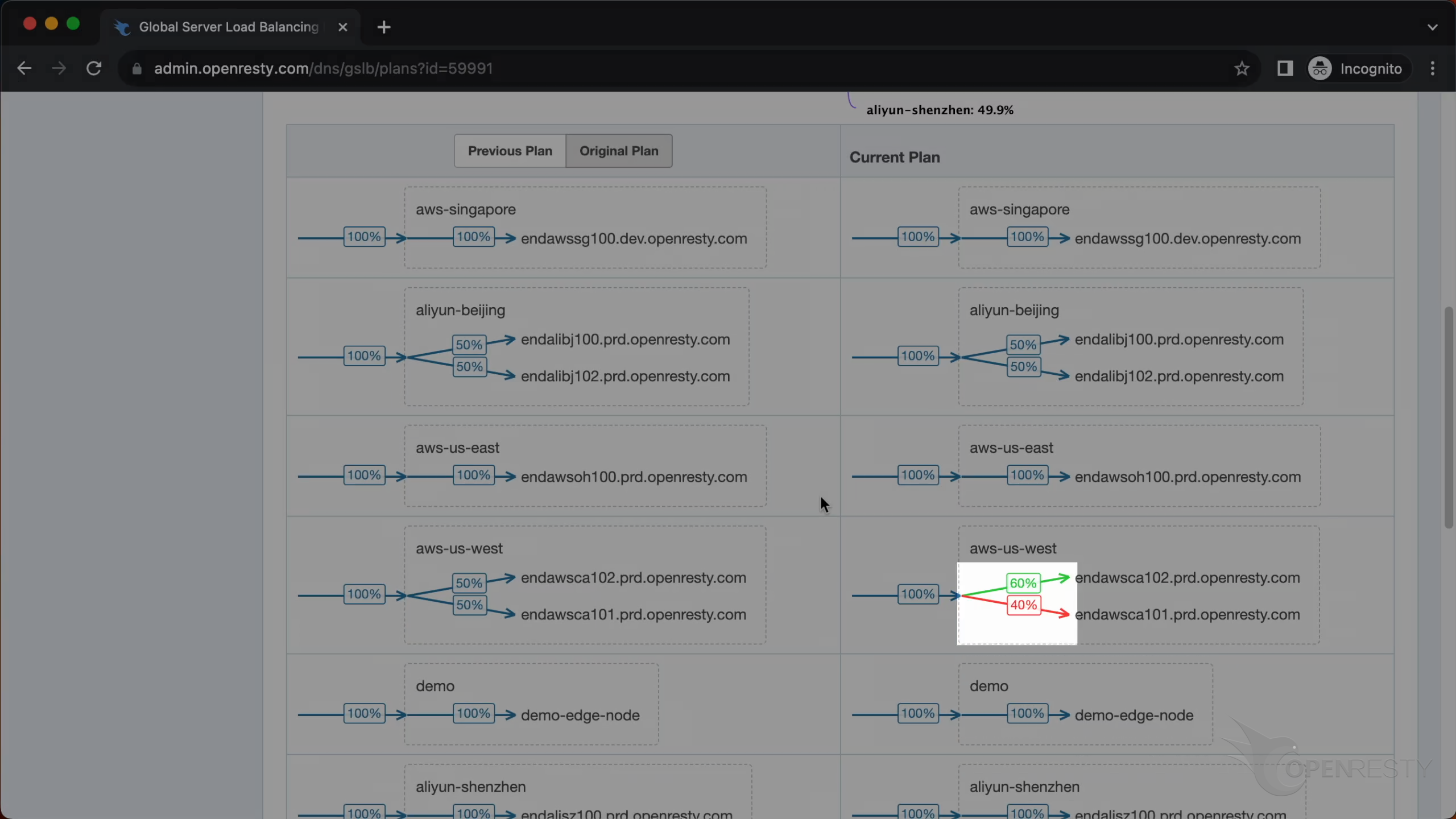
OpenResty Edge の GSLB は、直感的な可視化パネルを提供し、「なぜ振り分けが行われたのか」という疑問に明確に答えます。
- 計画比較:システムは、
元の DNS 計画と GSLB によるインテリジェントな調整後のGSLB 計画の違いを直感的に表示します。 - トラフィック変化の方向:可視化された重み変化のインジケーターを通じて、トラフィック移行の方向と増減幅を定量的に示します。視覚的に分かりやすい赤と緑の矢印により、システムがどのノードのトラフィックを減らし、どのノードのトラフィックを増やしているかを一目で把握できます。(緑は増加、赤は減少を示します)
- 履歴再現:システムは任意の過去時点の振り分けスナップショットを遡って表示できます。これにより、事故発生時のグローバルなトラフィック分布とスケジューラーの決定を正確に再現することが可能です。
可観測性は、自動化の単なる追加機能ではなく、その前提条件です。意思決定プロセスが監査可能で、かつ説明可能である場合にのみ、自動化された振り分けは真に生産環境の信頼できるシステムの一部として組み込まれることができます。
「アラート対応」から「予測可能なトラフィック制御」へ
GSLB が アプリケーション層の認識、円滑な トラフィック制御、そして意思決定プロセスの透明性を備えることで、運用保守の業務形態も大きく変化します。
| 運用シナリオ | 従来の方法 | OpenResty Edge GSLB |
|---|---|---|
| 負荷異常の検知 | 監視パネルを目視で確認し、手動で判断 | システムが アプリケーション層の指標を自動 モニタリング |
| 意思決定と応答時間 | 数分から 数十分(手動判断+操作+ DNS 反映) | 秒単位での自動応答 |
| ポリシー調整 | 手動で重みを変更し、経験則に基づいて調整を試みる | 事前設定された閾値に基づき、自動で段階的に調整 |
| ノード過負荷保護 | ヘルスチェック失敗後にサービスから切り離す(既に問題発生後) | 高負荷時に能動的に サーキットブレーカー を発動(未然防止) |
| 障害の事後分析 | ログと記憶を頼りに状況を把握する | 完全な意思決定履歴を遡及可能 |
| 夜間 オンコール | アラート処理のため、常時待機が求められる | システムがルールに基づき自動処理し、手動介入を低減 |
エンジニアの役割は、受動的にアラートに対応する「実行者」から、能動的にシステムを設計する「戦略立案者」へと転換します。その主要な業務は以下のようになります。
- ビジネスの「健全性」モデルを定義する(適切な アプリケーション層の指標を選択する)。
- システムの介入ポリシーを定義する(合理的な閾値と サーキットブレーカー 条件を設定する)。
スケジューリングロジックをコードとして実装し、制御プレーンがミリ秒単位のタイムウィンドウ内で「検出-意思決定-実行」のクローズドループを完了させます。手動介入によって生じる意思決定の遅延や誤操作のリスクと比較して、システム化された自動スケジューリングは、運用に必要な予測可能性と安定性を提供します。これは本質的に、運用チームを繰り返されるシステムの複雑化との戦いから解放し、その焦点を SSH での場当たり的な修正から、システムアーキテクチャの長期的なガバナンスへと転換させるものです。
もし貴社のアーキテクチャが以下の複雑性に関する課題に直面している場合、このアプリケーション層に着目したGSLBはその真価を発揮するでしょう。
- 多地域/多クラスターデプロイメント:これは GSLB の主要な適用領域であり、リソース利用率とディザスタリカバリ能力を最大化できます。
- ビジネスピークの予測不能性:頻繁に突発的なトラフィックが発生し、システムが迅速かつ自動的な弾力的なスケーリング能力を備えている必要があります。
- 非線形トラフィックの急増:不規則なトラフィックのスパイクに直面すると、通常の手段ではフィードバックループが往々にして長すぎます。貴社が必要としているのは、アラートに依存する手動プロセスではなく、エッジ側で即座に感知し、自動的に機能制限やピークカット戦略を実行できる制御システムです。
まとめ
最後に、OpenResty Edge GSLB の位置付けについて技術的なまとめを行います。これは、意思決定を掌握しようとする「脳」として捉えるべきではなく、むしろエッジ側で動作し、アプリケーション層の視点を持つランタイムと表現できます。定義されたポリシーセキュリティ領域内で、より短いフィードバックループを通じて、線形的なアプローチでトラフィックの変動を処理し、従来のスケジューリングにおける「二者択一的」な硬直した切り替えを回避します。
OpenResty Edge GSLB の核心的な価値は、スケジューリングを「全自動」にすることではなく、システムが負荷変動時に、粗雑な反応や遅延を起こさないようにすることにあります。多くの場合、システム安定性に求められるのは、このようなミリ秒単位のきめ細やかなガバナンス制御能力です。
もし貴社のシステムが、クロスリージョンでの高負荷トラフィックという課題に直面しており、既存のスケジューリング戦略の硬直性や弾力不足に苦慮されているなら、ぜひ一度、弊社のアーキテクトチームにご相談ください。
単なるツールの導入ではなく、貴社の実際のビジネスシナリオに基づき、OpenResty Edge を用いてどのように「滑らかなトラフィック制御」を実現できるか、具体的に解剖・提案させていただきます。
上記のスケジューリングロジックが OpenResty Edge で具体的にどのように実装されているか、またはその設定の柔軟性を検証されたい場合は、OpenResty Edge でグローバルサーバーロードバランシング(GSLB)機能を使用する方法の記事をご参照ください。このドキュメントは、基本的な導入から複雑なシナリオへの対応まで、包括的な操作ガイドを提供します。
OpenResty Edge について
OpenResty Edge は、マイクロサービスと分散トラフィックアーキテクチャ向けに設計された多機能ゲートウェイソフトウェアで、当社が独自に開発しました。トラフィック管理、プライベート CDN 構築、API ゲートウェイ、セキュリティ保護などの機能を統合し、現代のアプリケーションの構築、管理、保護を容易にします。OpenResty Edge は業界をリードする性能と拡張性を持ち、高並発・高負荷シナリオの厳しい要求を満たすことができます。K8s などのコンテナアプリケーショントラフィックのスケジューリングをサポートし、大量のドメイン名を管理できるため、大規模ウェブサイトや複雑なアプリケーションのニーズを容易に満たすことができます。
著者について
章亦春(Zhang Yichun)は、オープンソースの OpenResty® プロジェクトの創始者であり、OpenResty Inc. の CEO および創業者です。
章亦春(GitHub ID: agentzh)は中国江蘇省生まれで、現在は米国ベイエリアに在住しております。彼は中国における初期のオープンソース技術と文化の提唱者およびリーダーの一人であり、Cloudflare、Yahoo!、Alibaba など、国際的に有名なハイテク企業に勤務した経験があります。「エッジコンピューティング」、「動的トレーシング」、「機械プログラミング」 の先駆者であり、22 年以上のプログラミング経験と 16 年以上のオープンソース経験を持っております。世界中で 4000 万以上のドメイン名を持つユーザーを抱えるオープンソースプロジェクトのリーダーとして、彼は OpenResty® オープンソースプロジェクトをベースに、米国シリコンバレーの中心部にハイテク企業 OpenResty Inc. を設立いたしました。同社の主力製品である OpenResty XRay動的トレーシング技術を利用した非侵襲的な障害分析および排除ツール)と OpenResty Edge(マイクロサービスおよび分散トラフィックに最適化された多機能
翻訳
英文版 の原文と日本語訳版(本文)をご用意しております。読者の皆様による他の言語への翻訳版も歓迎いたします。全文翻訳で省略がなければ、採用を検討させていただきます。心より感謝申し上げます!
関連記事
OpenResty XRay Nov 13, 2023
機能の使用方法")
OpenResty XRay Mar 5, 2026

OpenResty XRay Feb 24, 2026

OpenResty XRay Dec 15, 2025

OpenResty XRay Dec 3, 2025














機能の使用方法")