Ylang:适用于 eBPF、Stap+、GDB 等框架的通用语言(第四集,全四集)
这篇文章是“Y 语言:适用于 eBPF、Stap+、GDB 等的通用语言”系列的第四集。其他集详见第一集、 第二集和第三集。
透明的跨容器追踪
Y 语言支持跨容器边界的透明追踪。它可以像常规的目标进程一样追踪 Docker 和 Kubernetes 容器。用户可以指定容器化进程的进程 ID 或进程组 ID进行追踪。OpenResty XRay 还可以自动检测同一主机内部运行的部分容器中的应用程序。
下面的这张屏幕截图展示了 OpenResty XRay 的 Web 控制台自动检测到的一个正运行在 Kubernetes 容器内部的 Perl 目标应用程序。
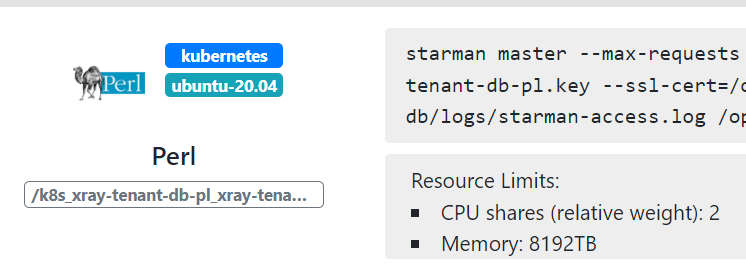
目标容器是不需要任何修改或者额外的权限的。这也是 100% 非侵入式动态追踪的美妙之处。
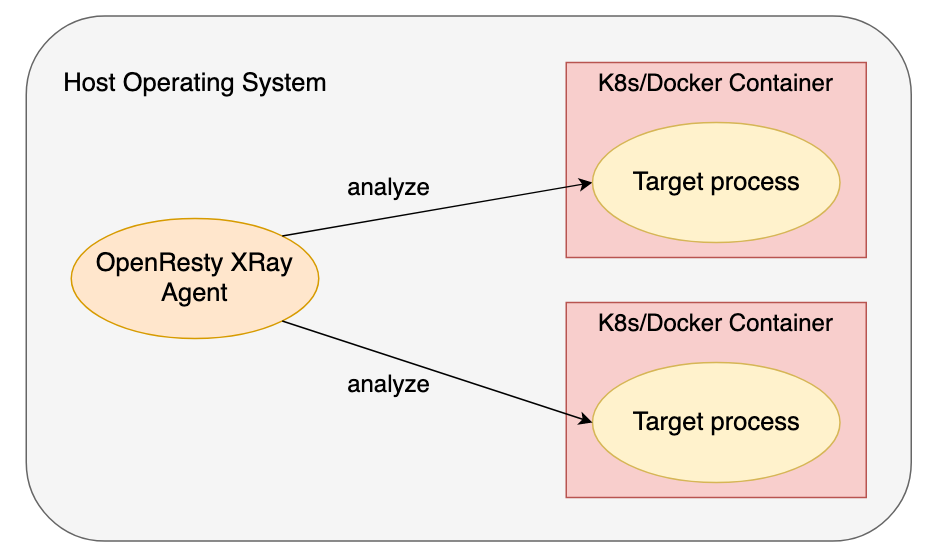
Y 语言 编译器生成的工具由 OpenResty XRay 的 Agent 守护进程执行和管理。后者可以透明地查看在同一主机操作系统中运行的任何 Docker 和 Kubernetes 容器,而无需目标容器本身的协作。
有些用户更喜欢在容器内运行 OpenResty XRay 的 Agent 进程。我们也支持这种方式,不过 Agent 容器必须是拥有特权的,否则它将没有权限检查其他容器(这也是特权容器的定义)。
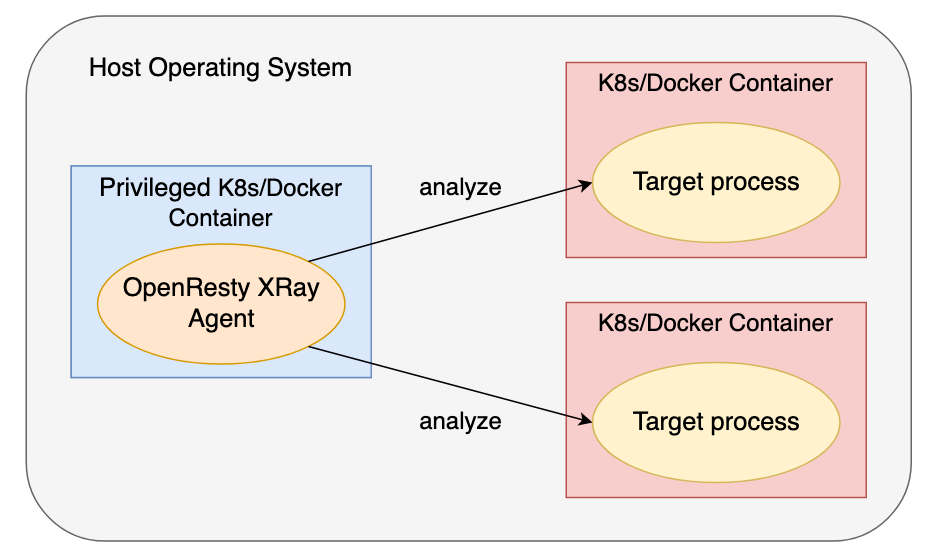
和往常一样,OpenResty XRay 不会注入任何代码或要求在目标进程中进行任何更改。目标容器中原有的安全隔离和权限不会受到任何损害。
高效的栈展开
Y 语言 编译器可以自动将栈展开(由 OpenResty XRay 的包数据库索引)编译成非常高效的本地代码,该代码执行时栈展开以生成运行时栈的调用栈轨迹或仅从当前运行时栈中读取特定的局部变量。
调用栈轨迹是至关重要的,因为它们为当前的代码执行上下文或”代码路径”提供了一种自然的呈现方式。它们是许多分析器的基石,其中包括为 CPU、延迟和内存使用情况的分析生成的火焰图。
以下是一个简单的 Y 语言 示例:
_probe usleep() {
_print(_sym_ubt(_ubt()));
}
在 C 函数 usleep 的入口点上放置一个动态探针,并打印出一个简易的 C 调用栈轨迹字符串。典型输出如下:
f95e0: usleep[1]
401134: main[0]
27082: __libc_start_main[1]
40106e: _start[0]
请注意,方括号([])中的整数数字表示目标程序模块文件的索引。0 表示主要的可执行文件,称为 a.out,而 1 则表示 a.out 所依赖的 libc-2.27.so 文件。用户可以在 OpenResty XRay 中快速获取实际的映射关系。
完整的 C 函数调用栈轨迹
Y 语言 的一些后端还支持内置函数 _print_full_ubt() 应用于所有的栈上的函数帧中,以参数和本地变量值的形式输出完整的调用栈轨迹。以下是一个示例:
_probe usleep() {
_print_full_ubt();
}
当使用 ODB 后端时,输出可能如下所示:
f95e0: usleep[1] (useconds=0x3)
ts=0x0
401134: main[0]
27082: __libc_start_main[1] (main=0x401126, argc=1, argv=0x7ffcd83d8378, init=<optimized>, fini=<optimized>, rtld_fini=<optimized>, stack_end=0x7ffcd83d8368)
result = <optimized>
unwind_buf=0x0
not_first_call = <optimized>
afct = <optimized>
head = <optimized>
cnt = <optimized>
__value = <optimized>
__value = <optimized>
ptr = <optimized>
__p = <optimized>
__result = <optimized>
40106e: _start[0]
这看起来与 GDB 的 bt full 命令的输出非常相似。
从 C 运行时栈读取特定变量值
完整的调用栈轨迹输出可能非常昂贵。有时,我们只需要从当前运行时栈中读取特定变量,这就会变得非常高效了。例如,如果我们使用 Y 语言 函数 _stack_var("r", 1) ,它将返回当前运行时栈(从时栈顶部到底部)名为 r 的第一个非优化本地变量的值(包括函数参数)。这个函数 _stack_var 目前还不在 OpenResty XRay 产品中提供,但它已经存在于我们的内部代码存储库中。一旦发布,我们将及时更新本文。
动态语言调用栈轨迹
Y 语言通过头文件提供标准库,用于生成动态语言的调用栈轨迹。动态语言包括 Lua、PHP、Python 和 Perl 等脚本语言。一些高级静态类型语言,比如 Go (golang)、Rust 和 C++ 也是支持的。未来还将支持更多语言,例如 Ruby、Java(JVM)、JavaScript(NodeJS)、OCamel、Haskell 和 Erlang 等等。
接下来,我们将说明如何打印 Lua 和 PHP 语言的调用栈轨迹。
Lua 调用栈轨迹
例如,当某些 Lua 代码在 LuaJIT 2.1上运行时,我们可以编写以下代码生成 Lua 级别的调用栈轨迹字符串:
#include "lj21.y"
_probe lj_cf_os_exit() {
printf("%s", lj_dump_bt(NULL, "min"));
}
在这里,我们把一个动态探针放在 C 函数 lj_cf_os_exit() 的入口点上,然后以最小化格式输出 Lua 级别的调用栈轨迹。这是一个示例输出:
$ run-y -c 'luajit test.lua'
test.lua:c
test.lua:b
test.lua:a
test.lua:0
C:pmain
test.lua 文件如下所示:
local function c()
local baz = "hello"
os.exit(0)
end
local function b()
local bar = 3.14
c()
end
local function a()
local foo = 32
b()
end
a()
Lua 函数 os.exit() 将触发 LuaJIT 虚拟机内部的 C 函数 lj_cf_os_exit() 。
由 OpenResty XRay 提供的 Lua 级别火焰图分析器使用类似的 Y 语言代码来生成火焰图。这是一个示例图表:
完整的 Lua 调用栈轨迹
我们可以通过上述提到的 Y 语言 程序中编写 lj_dump_bt(NULL, "full") 来获取完整的 Lua 调用栈轨迹,这其中包含每个 Lua 函数栈帧中本地 Lua 的变量值。针对上面示例的脚本 test.lua ,以下是一个示例输出:
[builtin#os.exit]
exit
test.lua:3
baz = "hello"
test.lua:c
test.lua:8
bar = 3.140000
test.lua:b
test.lua:13
foo = 32
test.lua:a
test.lua:16
c = function @test.lua:1: (GCfunc *)0x7feff0851578
b = function @test.lua:6: (GCfunc *)0x7feff0851658
a = function @test.lua:11: (GCfunc *)0x7feff08516c8
C:pmain
即使 Lua 标准库在默认情况下也不支持完整的调用栈轨迹。Y 语言 也无需 LuaJIT 虚拟机或目标进程配合与协议,因为它了解 LuaJIT 虚拟机的内部。
PHP 调用栈轨迹
以下是一个用于转存 PHP 7 的调用栈轨迹示例:
#include "php7.y"
_probe _timer.profile {
printf("%s\n", php7_dump_bt());
_exit();
}
这是一个示例输出:
C:sapi_cli_single_write
Application->setLogger
/tmp/test.php:24
C:sapi_cli_single_write
Application->getLogger
/tmp/test.php:30
C:sapi_cli_single_write
class@anonymous@/tmp/test.php:24$0->log
/tmp/test.php:30
与开源工具链的比较
SystemTap 直接将栈展开(通常以 DWARF 格式)嵌入到其编译后的工具中,并在运行时解析栈展开。这种方式速度很慢,是因为栈展开格式(例如 DWARF )是一种复杂的数据格式1,而且通常是为了紧凑性和空间利用率来优化,并不是为了速度。 Y 语言 是一个真正的编译器,它将 DWARF 数据转换为专用的本地代码并且以尽可能快的速度运行。 GDB 也同样解析 DWARF 数据,而不是作为一个实际的编译器工作。
Linux 的 perf 将完整的运行时栈内存内容复制到用户态以进行栈展开,但这种方式有以下缺点:
它可能会从内核空间复制过多的数据到用户态,并且大部分数据对于运行时的栈展开都是无用的。这种复制操作可能会很快跑满内存总线,并暴露敏感数据,易受安全漏洞的威胁。
复杂的工具无法直接在内核空间中利用调用栈轨迹。
而开源的 eBPF 工具链依赖于要在目标程序中使用的帧指针寄存器2,这与 x86_64 的 ABI 规范相违背。用户也不得不使用 C/C++ 编译器标志 -fno-omit-frame-pointer 重新编译大多数目标程序,这就又违反了动态追踪的黄金法则:不需要目标程序禁用优化,也不需要目标程序专门配合。
开源工具链均不支持栈展开动态语言的函数来调用运行时栈或者是生成它们的调用栈轨迹。
分析已终止进程( Core Dumps 文件 )
Y 语言的 GDB 后端对于分析已崩溃的进程生成的 core dump 文件是非常有用的。至于其他后端,如 Stap+ 和 eBPF ,均不支持 core dump 文件。
这是第一次,相同的分析工具可以分析活动进程和已终止的进程。这要归功于高级语言 Y 语言 ,相同的分析工具首次可以同时分析活动进程和死亡进程。
当 Y 语言 用于 core dumps 的分析器中,除了 _oneshot 和 _begin 之外,指定任何其他探针几乎没有意义。毕竟,core dump 是已终止进程的“残骸”3。
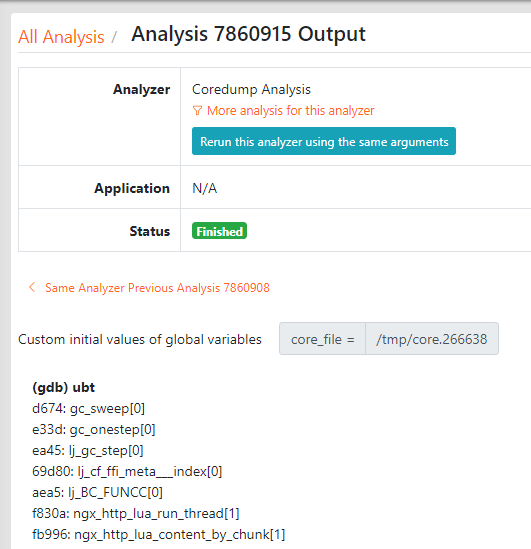
我们还计划添加一个新的 Y 语言 后端,以支持 Red Hat 的 crash 命令行实用程序,这样我们就可以使用 Y 语言 来调试 Linux 内核的崩溃转存文件(例如来自 kdump 的文件)。如此一看,分析操作系统内核的"残骸"也是一个有趣的步骤。
极低的追踪开销
动态追踪具有极低的运行时开销,因为它只收集特定分析目标所需的信息。这与传统方法在日志数据中收集尽可能多的信息4的方式截然不同。后者是由于写入和传输大数据而产生更高的开销 5。
通常来讲,动态追踪也基于采样的方式。因为它从不注入任何代码或加载特殊模块到目标进程中,所以当不进行采样时,它的开销严格为零。大多数分析工具的开销通常是不可测量的,即使在采样窗口期间也是如此。当目标应用程序达到最大吞吐量时,采样成本通常低于吞吐量的 5%。一些全量检测工具可能会产生更高的开销,比如超过最大应用程序吞吐量的 30% 以上。然而,当在线性能已经降至极低水平时,我们也仍然可以在生产环境中使用它们。
Y 语言还是一个优化编译器,可以为不同的后端生成紧凑且高效的代码。例如,由 Y 语言 的 GDB 后端生成的 Python 代码以接近四倍的速度快于手工编写的代码6。
标准的 Y 语言库和工具
正如我们在前面的部分中所看到的,Y 语言 提供了标准的头文件来应用于导入更多函数和其他功能,类似于 C/C++ 的中的代码重用方式。我们已经看到了像 lj21.y 和 php7.y 这样的标准头文件,它们构成了 Y 语言 的标准库。我们同样会使用 Y 语言 来实现这些标准库。
未来,我们将会 Y 语言7中支持使用多个编译单元以减少编译器必须重新编译的代码量。
另外,OpenResty XRay 提供了许多不同类型的开源软件的标准分析器或工具,其中大多数工具都是用 Y 语言 编写的。有些甚至是用如 YLua 和 YSQL 等更高级的语言编写的。我们拥有可以在 Y 语言 之上构建语言抽象形式的整条“食物链”。例如,使用 Lua 语法来操作 Lua 级别的数据结构比使用 C 语法来检查 C 级别的数据结构更加自然。
网络过滤和控制
您也可以使用 Y 语言 编写在内核中运行的网络程序,以操控和处理网络数据包。这要归功于 Linux 内核网络协议栈中的 eBPF 支持。eBPF 的前身 BPF 专门用于网络过滤。有了 Y 语言 和 OpenResty XRay 的 eBPF 工具链,我们不再受制于原始 eBPF 工具链和虚拟机实现中的痛苦限制。我们有能力将强大的程序连接到 XDP 和 TC 子系统。
这个功能目前已经在 OpenResty XRay 中实现。并且 OpenResty DDoS 幻灯片也可以在我们 OpenResty Edge 的产品页面中找到。
Y 语言编译器的实现
Y 语言 编译器是用 Fan 语言(或称 fanlang)编写的,Fan 语言是我们专门设计用于实现通用和特定领域语言的优化编译器的 Perl 6(或 Raku)方言语言。Fanlang 编译器生成了优化过的 LuaJIT 字节码,运行速度比 Rakudo8等开源的 Perl 6 实现要快得多。Fanlang 编译器也将很快成为我们的 OpenResty Edge 和 OpenResty Plus 产品的一部分。
操作系统支持
Y 语言和 OpenResty XRay 支持大多数仍在维护生命期中的主流 Linux 发行版。而一些已经达到生命期终点的发行版版本,比如 Ubuntu 14.04 和 CentOS 6,在某种程度上来说仍然是可用的。
下一个将得到支持的大型操作系统版本是 Android,因为它的内核本质上就是基于 Linux 的。Y 语言 的 eBPF+ 后端也即将在该平台上直接运行。
我们还计划支持更多不太常见的操作系统,如 *BSD 和 macOS。Windows 从技术上讲也是有可能实现的。请继续关注我们的最新动态!
对开源社区的贡献
我们创建了 Y 语言 和 OpenResty XRay 来帮助排查和优化各种开源软件。如今,开源软件无处不在,但很少有人对自己日常使用和喜爱的开源软件有真正深入的了解。甚至许多人可能没有正确地利用这些开源软件,或者使用方式不够优化。Y 语言 和 OpenResty XRay 本身也利用了大量高质量的开源代码。
Y 语言使得创建极其复杂的分析器和工具变得轻而易举,这对底层的开源基础设施带来了前所未有的压力。事实上,我们在几乎所有使用的开源组件中都遇到了许多难以理解的问题,比如 SystemTap、Clang/LLVM、libbpf、GDB 和 Linux 内核(包括 eBPF 机制、perf 事件、libbpf、btftool等)。
我们一直在积极向这些开源项目汇报问题并提交修复补丁,以帮助改进和优化开源社区。在这里特别感谢 SystemTap 项目的作者 Frank Ch. Eigler,他迅速审查并接受了我们的补丁,并在多年来一直给予了我们大力支持。我们也一直主导着我们的开源项目,比如 OpenResty,并且对开源运动的价值抱有巨大的信心。
结论
Y 语言是一个通用的调试和动态追踪语言,针对许多不同的调试框架和运行时环境。此外,Y 语言 使用的后端还解决了许多开源对应产品(如果有对应产品)的限制,也同时添加了许多新功能。现在开发新的动态追踪工具变得更加容易了。用户可以通过 OpenResty XRay 产品使用 Y 语言 和工具链,或者使用我们编写的 Y 语言 标准分析器。
本系列文章以简单的示例为您介绍了 Y 语言 的特点和优势的高层次概述,并提供了简单的示例。您可以在官方文档中找到有关 Y 语言 的更多详细信息。
致谢
我们的工作是站在许多动态追踪和调试领域的巨人肩膀上的。
Brendan Gregg 的博客在 2012 年首次引起了我的兴趣,当时他主要谈论 DTrace。近年来,他在 Linux 的 eBPF 和 perf 工具链领域的工作仍然激励着我们。
2012 年至 2016 年期间,我在 Cloudflare 工作时,Cloudflare 为我们提供了一个巨大的实验场,以应用动态追踪技术来解决大规模云环境中的实际问题。
Frank Ch. Eigler 的 SystemTap 提供了最强大的开源动态追踪框架,在早期给我提供了很大的帮助。多年来,我们也一直与 Frank 和其他 Red Hat 的 SystemTap 开发工程师们密切合作。
致力于 Linux 的 eBPF 工作的人们同样值得敬佩。他们将 DTrace 的内核虚拟机的强大功能引入 Linux 内核,并将其扩展到网络和跟踪领域。
特别感谢我们的 OpenResty Inc. 开发工程师们,使 Y 语言 和 OpenResty XRay 成为现实。同时,还要感谢所有我们的 OpenResty XRay 用户,每天都在帮助改进产品。
最后,我也同样要感谢的是,21 世纪初在 Sun Microsystems 创建 DTrace 的开发工程师们。他们的这一创新掀开了计算机世界的崭新篇章。
关于作者
章亦春是开源 OpenResty® 项目创始人兼 OpenResty Inc. 公司 CEO 和创始人。
章亦春(Github ID: agentzh),生于中国江苏,现定居美国湾区。他是中国早期开源技术和文化的倡导者和领军人物,曾供职于多家国际知名的高科技企业,如 Cloudflare、雅虎、阿里巴巴, 是 “边缘计算“、”动态追踪 “和 “机器编程 “的先驱,拥有超过 22 年的编程及 16 年的开源经验。作为拥有超过 4000 万全球域名用户的开源项目的领导者。他基于其 OpenResty® 开源项目打造的高科技企业 OpenResty Inc. 位于美国硅谷中心。其主打的两个产品 OpenResty XRay(利用动态追踪技术的非侵入式的故障剖析和排除工具)和 OpenResty Edge(最适合微服务和分布式流量的全能型网关软件),广受全球众多上市及大型企业青睐。在 OpenResty 以外,章亦春为多个开源项目贡献了累计超过百万行代码,其中包括,Linux 内核、Nginx、LuaJIT、GDB、SystemTap、LLVM、Perl 等,并编写过 60 多个开源软件库。
关注我们
如果您喜欢本文,欢迎关注我们 OpenResty Inc. 公司的博客网站 。也欢迎扫码关注我们的微信公众号:

翻译
我们提供了英文版原文和中译版(本文)。我们也欢迎读者提供其他语言的翻译版本,只要是全文翻译不带省略,我们都将会考虑采用,非常感谢!
例如,在 x86_64 架构上,帧指针寄存器是
rbp。 ↩︎我们拥有专有技术,可以通过将 core dump 文件加载到复活的进程中,使已崩溃的进程复活。您可以自由使用 Y 语言 中的所有探针,如函数探针和系统调用探针来进行追踪。 ↩︎
日志数据可以存储在文件系统上,也可以实时发送到网络上。 ↩︎
这需要大量的 CPU 时间、内存带宽、磁盘/网络带宽等等。 ↩︎
由 Y 语言 编译器生成的 GDB Python 代码不使用 ``gdb.Value
或gdb.Type` 对象,这非常明显地减少了运行时开销。人类无法编写这样的 Python 代码,因为这对于生物大脑来说太复杂了。 ↩︎它也类似于 C 和 C++ 语言。 ↩︎
相关文章
OpenResty XRay Aug 22, 2023

OpenResty XRay Aug 21, 2023

OpenResty XRay Jul 6, 2023

OpenResty XRay Nov 24, 2023
")
OpenResty XRay Aug 6, 2023
")















")
")
{kind=link}