一次无法重启的 Nginx 内存泄漏,我们是如何在生产环境把它抓出来的
你的生产环境是否也遇到过这样的问题?一个基于 Nginx 或 OpenResty 的核心网关,在没有任何明显流量异常的情况下,内存占用却像被施了魔法一样,缓慢而坚定地向上攀升。
几天过去,单个 worker 进程的内存就从几百兆涨到了 1G 以上,系统 OOM (Out of Memory) 的警报随时可能被触发。最棘手的方案似乎只剩下那个“重启大法”,但这在核心业务上无异于饮鸩止渴——它能暂时缓解问题,却无法根除,更重要的是,你根本不知道下一次危机何时到来。这就是我们最近处理的一个真实案例。一个高并发的 API 网关,正面临着同样的困境。这篇文章将分享我们是如何在不重启服务、不影响业务的前提下,精准定位并拆解这个深藏在 Nginx 内部的内存泄漏问题。
要破解这个困局,关键不在于“我该用什么工具”,而在于先建立一条清晰、可验证的分析路径。我们采用的是一种自顶向下、层层收敛的方法论。不是为了更快,而是为了在生产环境中获得确定性。
一次生产环境内存泄漏的完整解剖
Step 1:系统层现象确认 → 分配器归因
首先,我们从系统层入手,确认内存增长的真实载体。通过运行 OpenResty XRay的引导式分析功能,对高内存问题进行自动分析。从自动分析报告的结果可以明确看到:Nginx worker 进程的内存使用已经超过 1GB,并且仍在持续增长。
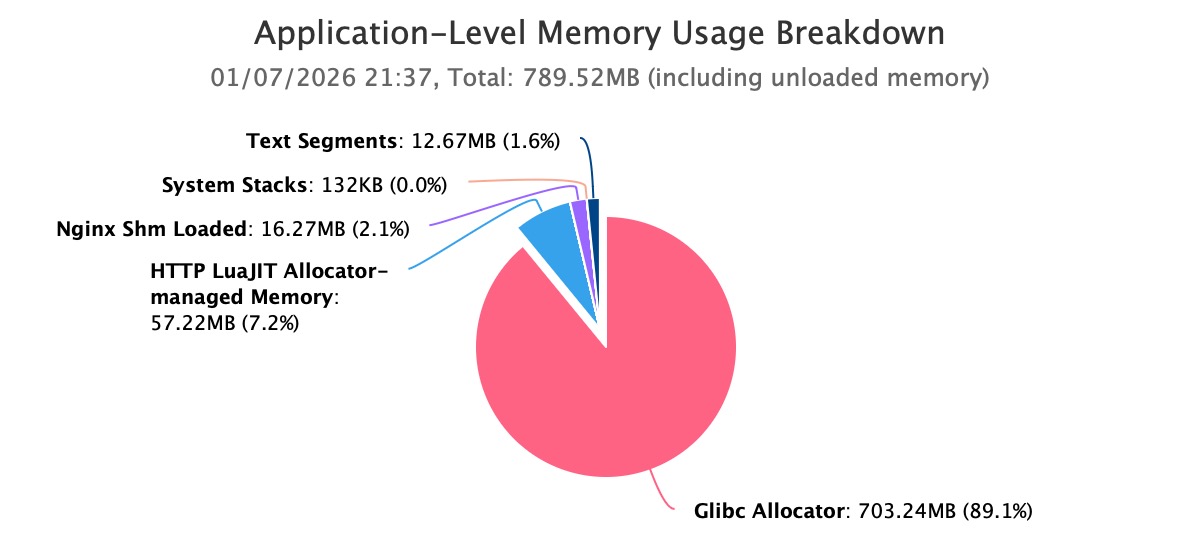
进一步的分解显示,这部分内存开销中,绝大多数由 Glibc Allocator 持有。这一步直接排除了内核缓存、文件系统或其他外围组件的问题,将焦点牢牢锁定在应用进程自身的内存分配行为上。
这一结论至关重要。它排除了内核态泄漏、文件缓存或外部进程干扰等可能性,将问题的边界清晰地收敛到了应用自身的内存分配行为。
Step 2:分配器归因 → Nginx 内存池聚焦
既然内存主要由 Glibc 持有,而进程是 Nginx,那么这些内存服务于 Nginx 的内存池体系的可能性最大。真正困难的地方在于:Glibc 之下的内存,究竟是被哪些 Nginx 内存池消耗的?
通过对 Nginx 内存池的专项分析,我们很快发现了异常集中点。
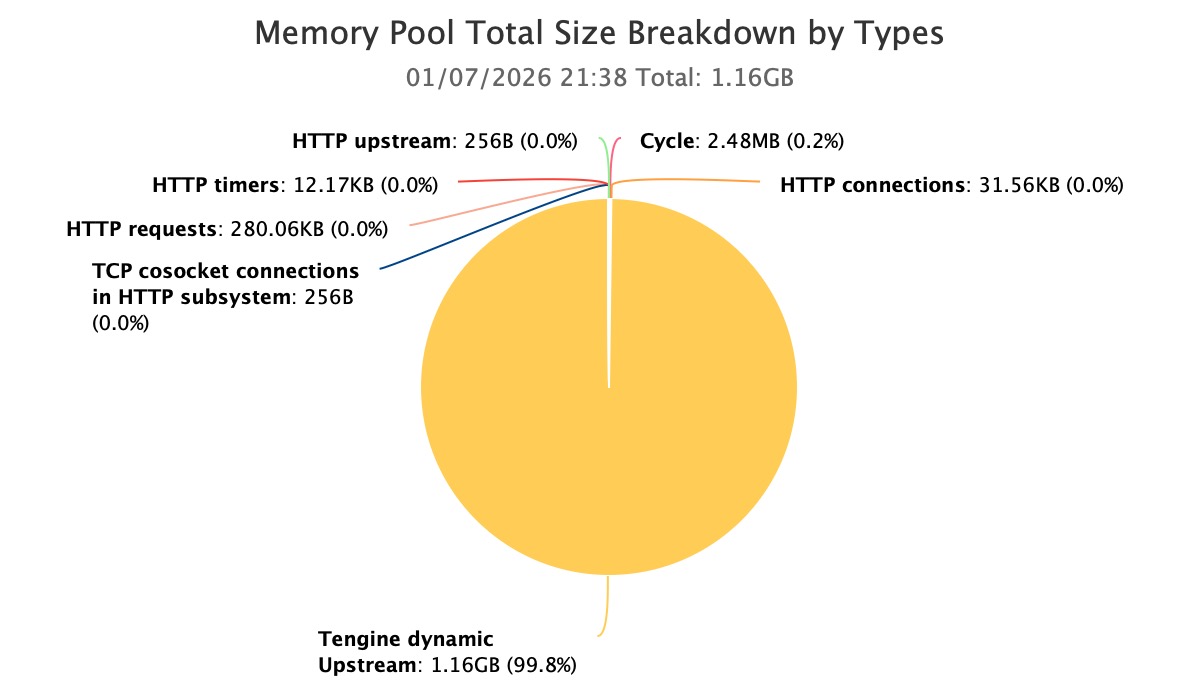
当前进程中,主要的内存消耗来自 Tengine dynamic upstream 模块所创建的 Nginx 内存池。
至此,问题第一次从“进程级内存失控”,收敛为“某一类内存池的异常增长”。
Step 3:Nginx 内存池聚焦 → 模块级怀疑
在确认了问题集中于 dynamic upstream 相关的内存池后,我们进一步下钻到 Glibc 分配器层面,再次运行 OpenResty XRay 对内存块尺寸分布进行分析。
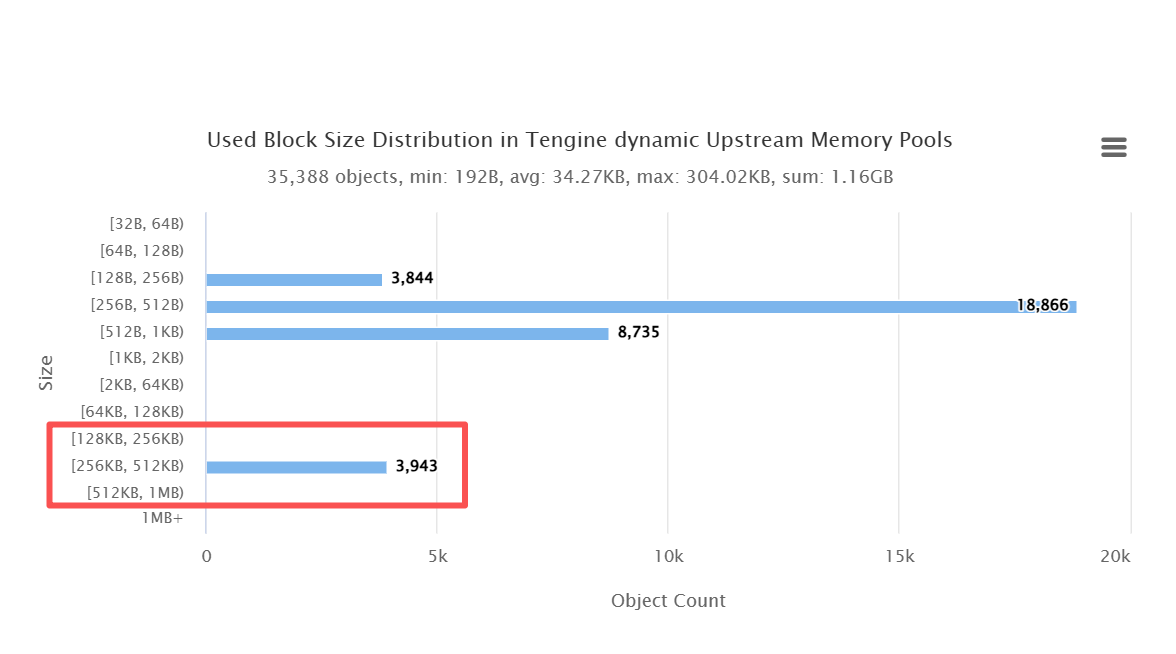
结果非常明确:在 256k–512k 这个区间内,存在 2240 个内存块,数量显著偏离正常运行时的分布特征。这种尺寸的大量聚集,意味着这些内存并非短生命周期对象,而是被长期持有、且没有得到释放。
这一发现,为“内存泄漏”提供了强有力且可量化的证据,而不再只是经验判断。
Step 4:模块级怀疑 → C 代码调用链追溯
确定了异常内存池,也确认了异常内存块形态,最后一步便是回答最核心的问题:这些内存究竟是在哪一条代码路径上被分配,并最终失去了释放的机会?
通过使用 c-memory-leak-fgraph 工具,我们将内存池的分配行为,完整映射回 C 代码层面的函数调用关系。一条清晰、完整的内存泄漏调用链随之浮现,从内存分配点开始,贯穿模块逻辑,直至生命周期断裂的位置。
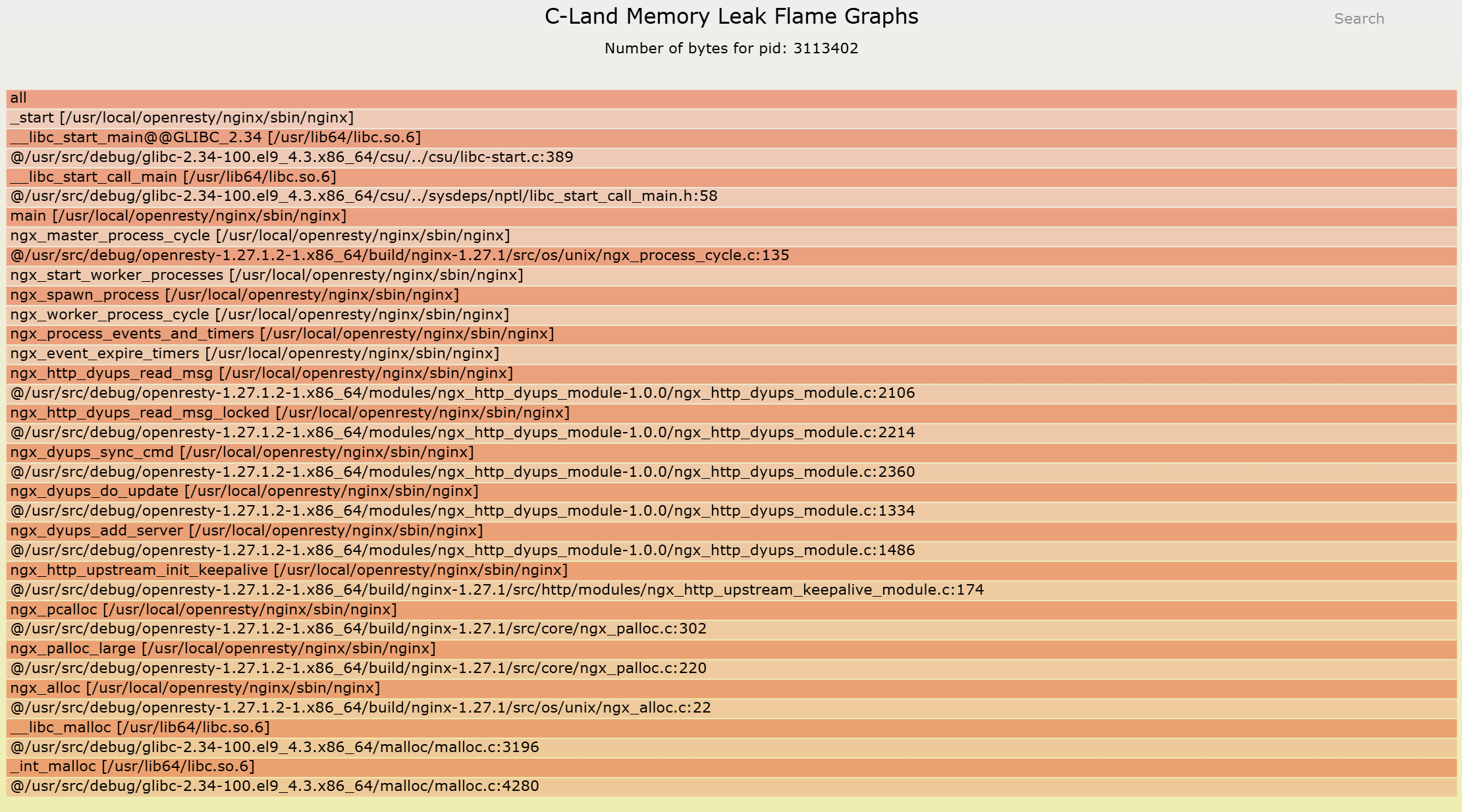
这一刻,问题不再是“可能在哪里”,而是“它就是在这里发生的”。
我们能够在不重启、不影响生产流量的前提下,将一个深埋在 Nginx 内存池内部的泄漏问题,完整、准确地还原为一条可追溯的 C 代码调用路径。不再依赖猜测,不再依赖重启换时间,而是掌握了可以被验证、可以被修复的确定性证据。
这条分析路径本身并不复杂,但它有一个严格前提:必须能够在生产环境中,安全地跨越 Glibc 分配器、Nginx 内存池以及 C 代码三层边界进行观测与关联。
也正是在这种真实而苛刻的场景下,OpenResty XRay 专业性能工程能力的价值,才真正显现出来。
为什么这类问题几乎无解?
大多数团队在面对这类问题时,往往束手无策。这并非技术实力不足,而是因为问题的复杂性超出了常规工具和知识的范畴。
1. Nginx 内存池:一个黑盒
与我们熟悉的 malloc/free 不同,Nginx 为了性能,设计了一套自己的内存池(Memory Pool)。内存的申请和释放被 Nginx 托管,这意味着 valgrind 这类传统的内存泄漏检测工具几乎完全失效。它们无法理解 Nginx 内存池的生命周期,强行在生产环境使用 valgrind 更是一种自杀行为,会带来毁灭性的性能影响。
2. Glibc 分配器:问题的“藏身之所”
更深一层,Nginx 内存池本身也是构建在 Glibc 的 malloc 之上。当泄漏发生时,我们能从 top 或 pmap 看到的,只是 Glibc 分配器持有的内存总量在增长。而在本案中,问题被巧妙地隐藏在了大量 256k-512k 的内存块中,从外部看,你根本无法将这些内存块与 Nginx 内部的任何具体对象关联起来。
3. 动态模块的复杂性
此案例中的服务使用了 Tengine 的动态上游(dynamic upstream)模块。这类模块的特点是其内部对象具有复杂的、长生命周期的管理逻辑。当这些逻辑与 Nginx 的事件驱动、异步 I/O 模型结合时,内存的分配和释放在不同的代码路径和时间点上,追踪难度呈指数级增长。
这三座大山,让工程师陷入了“错误尝试”的循环:调整内核参数 drop_caches?治标不治本。增加 worker_rlimit?迟早都会崩溃。最终,只剩下那个让 SRE 团队夜不能寐的 systemctl restart nginx。
在这种时刻,工程师们往往会形成一个清醒却无力的共识:我们知道有问题,但我们看不见它。不是不知道内存正在增长,而是不知道它为什么增长,更不知道该在哪里下刀。
从“靠运气”到“可预测”
定位并修复这个 bug 带来的价值,远不止是节省了内存。它代表着系统从一个“靠运气运行”的状态,演进为一个“健康可预测”的系统。基于我们的经验,这类修复通常会带来显著的量化收益:
内存与可用性收益:
- 内存占用降低 70-90%:worker 进程内存从超过 1G 稳定在 200-300MB 水平。
- 杜绝 OOM 崩溃:服务可用性从 99.5%(依赖定期重启)提升至 99.9%+ 的稳态。
性能与成本收益:
- 运维成本降低 50%+:告警风暴消失,SRE 团队无需再为内存问题投入无效的排查和重启操作。
- 硬件成本优化:基于更低的内存占用,未来可节省 30-50% 的服务器内存配置。
核心价值在于:它将一个可能导致每月数万元业务损失的定时炸弹,彻底拆除了。
当性能问题超越“工具”范畴
这个案例完美诠释了一个观点:当系统复杂度超过某个阈值,性能问题已经不再是单纯的“工具问题”,而是“方法论 + 经验密度”的综合挑战。
传统工具之所以失效,是因为它们被设计用来解决更简单、更通用的问题。而面对 Nginx 内存池与 Glibc 分配器交织的复杂场景,你需要的是 OpenResty XRay 这样能够深入系统“毛细血管”的洞察力,以及在不中断服务的前提下完成诊断的工程经验。
这也解释了为什么即使是技术实力雄厚的团队,在面对某些棘手的性能瓶颈时,仍然需要专业的性能工程师介入。因为他们带来的不仅仅是工具,更是一种能够将复杂问题系统化、可视化的工程方法论。
关于 OpenResty XRay
OpenResty XRay 是一款动态追踪产品,它可以自动分析运行中的应用,以解决性能问题、行为问题和安全漏洞,并提供可行的建议。在底层实现上,OpenResty XRay 由我们的 Y 语言驱动,可以在不同环境下支持多种不同的运行时,如 Stap+、eBPF+、GDB 和 ODB。
关于作者
章亦春是开源 OpenResty® 项目创始人兼 OpenResty Inc. 公司 CEO 和创始人。
章亦春(Github ID: agentzh),生于中国江苏,现定居美国湾区。他是中国早期开源技术和文化的倡导者和领军人物,曾供职于多家国际知名的高科技企业,如 Cloudflare、雅虎、阿里巴巴, 是 “边缘计算“、”动态追踪 “和 “机器编程 “的先驱,拥有超过 22 年的编程及 16 年的开源经验。作为拥有超过 4000 万全球域名用户的开源项目的领导者。他基于其 OpenResty® 开源项目打造的高科技企业 OpenResty Inc. 位于美国硅谷中心。其主打的两个产品 OpenResty XRay(利用动态追踪技术的非侵入式的故障剖析和排除工具)和 OpenResty Edge(最适合微服务和分布式流量的全能型网关软件),广受全球众多上市及大型企业青睐。在 OpenResty 以外,章亦春为多个开源项目贡献了累计超过百万行代码,其中包括,Linux 内核、Nginx、LuaJIT、GDB、SystemTap、LLVM、Perl 等,并编写过 60 多个开源软件库。
关注我们
如果您喜欢本文,欢迎关注我们 OpenResty Inc. 公司的博客网站 。也欢迎扫码关注我们的微信公众号:

翻译
我们提供了英文版原文和中译版(本文)。我们也欢迎读者提供其他语言的翻译版本,只要是全文翻译不带省略,我们都将会考虑采用,非常感谢!
相关文章
OpenResty XRay Jul 16, 2025

OpenResty XRay Dec 23, 2025

OpenResty XRay Sep 1, 2025

OpenResty XRay Jul 8, 2025

OpenResty XRay Jul 15, 2023















