如何使用 OpenResty XRay 快速定位 C++ 模块中的内存泄漏
在某些关键时刻,核心服务的稳定性直接关系到业务的成败。最近,我们的一位客户就遇到了让运维团队头疼的问题:Nginx 服务的内存像“黑洞”一样不断膨胀。临时重启只能缓解一时压力,问题却总是死灰复燃。我们将通过这篇文章分享如何用 OpenResty XRay 快速发现并定位这一隐蔽的内存泄漏问题,以及如何把复杂、漫长的内存泄漏定位过程,赋能成一个“诊断 → 规划 → 验证”可复用的闭环。
技术困境与初步诊断
我们一位客户的核心 Nginx 服务内存占用持续上涨,仿佛一个“内存黑洞”。虽然临时重启能缓解一时的压力,但问题很快再次出现。
挑战与风险:
- 技术层: 生产环境下的 C/C++ 模块内存泄漏,堪称最难解决的问题之一。传统调试工具(如 GDB)无法直接用于线上,而代码审计则如同大海捞针,耗时且低效。
- 业务层: 如果放任不管,内存消耗会持续加剧,导致 响应变慢、频繁崩溃,最终威胁核心业务的连续性。这意味着:用户体验下降,用户逐渐流失;品牌声誉受损和直接的经济损失。
靠定时重启来“续命”,无异于饮鸩止渴,让整个业务长期暴露在风险之中。在接到求助后,我们立即利用动态追踪产品 OpenResty XRay 直接在生产环境对内存分配进行分析。仅仅几分钟,工具就自动生成了内存泄露火焰图,为问题排查提供了清晰的突破口。
火焰图一目了然地显示了内存分配主要集中在三个区域:
- Nginx 内存池
- TLS 相关内存
ngx_dubbo_module函数
Nginx 内存池和 TLS 都是久经考验的成熟组件,发生内存泄漏的概率极低。因此,我们将分析的重点迅速锁定在嫌疑最大的 ngx_dubbo_module 函数上。
火焰图指路,锁定内存泄漏的“重灾区”
第一步:锁定可疑函数。
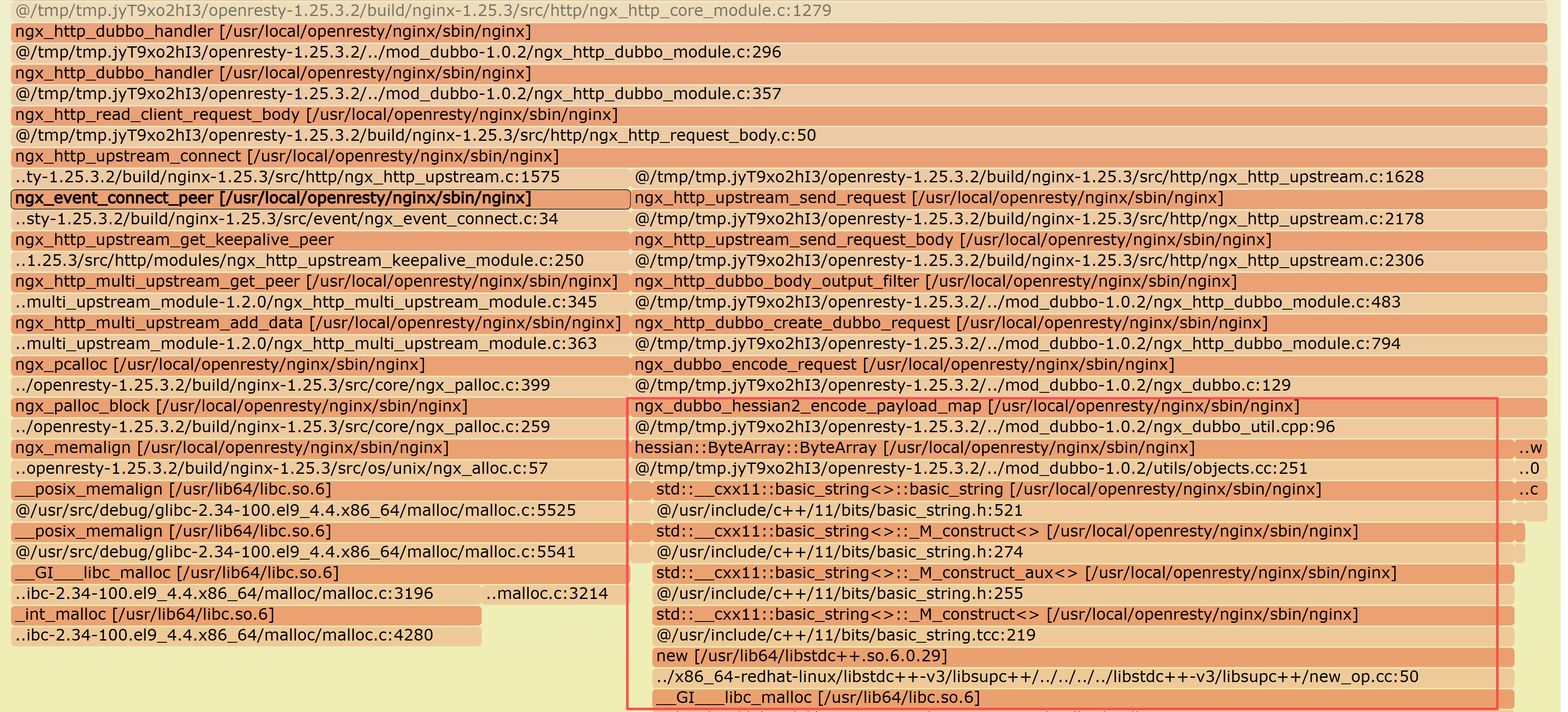
借助 OpenResty XRay 的强大动态追踪能力,我们不需要翻阅海量日志或进行地毯式代码审计,就能像“庖丁解牛”一样高效地剖析问题,我们 zoom in 嫌疑最大的 ngx_dubbo_module 函数。

内存泄露火焰图清晰地指出,内存分配的峰顶指向了 ngx_dubbo_hessian2_encode_payload_map 函数,这里就是内存泄漏的“重灾区”。
第二步:深入代码,发现疑点。
我们定位到该函数的源码,很快就发现了可疑之处:
ngx_int_t ngx_dubbo_hessian2_encode_payload_map(ngx_pool_t *pool, ngx_array_t *in, ngx_str_t *out)
{
try {
// ...
for (size_t i=0; i<in->nelts; i++) {
string key((const char*)kv[i].key.data, kv[i].key.len);
if (0 == (key.compare("body"))) {
// 这里用 new 创建了对象
ByteArray *tmp = new ByteArray((const char*)kv[i].value.data, kv[i].value.len);
ObjectValue key_obj(key);
ObjectValue value_obj((Object*)tmp);
// 将对象放入 Map,但之后没有看到 delete 操作
strMap.put(key_obj, value_obj);
} else {
// ...
}
}
// ...
} catch (...) {
// ...
}
}
代码中使用 new ByteArray 创建了 tmp 对象,但通读全篇,我们都没有找到与之对应的 delete 操作。直觉告诉我们,问题就出在这里。tmp 对象被包装成 ObjectValue 后,传递给了 strMap.put 方法。它的生命周期到底由谁管理?
第三步:顺藤摸瓜,追溯对象生命周期。
为了弄清真相,我们必须深入到 hessian2 库的实现细节中。
首先,tmp 指针被用来构造 ObjectValue:ObjectValue value_obj((Object*)tmp);,其对应的构造函数非常简单,只是将指针存起来,并未涉及任何智能指针或所有权转移的操作。
// ObjectValue 构造函数
ObjectValue(Object* obj) : _type(OBJ) { _value.obj = obj; }
接着,value_obj 被传入 strMap.put 方法。这个方法内部会调用 value.get_object() 来获取原始的对象指针:
// Map::put 方法实现
void Map::put(const ObjectValue& key, const ObjectValue& value,
bool chain_delete_key, bool chain_delete_value) {
pair<Object*, bool> ret_key = key.get_object();
pair<Object*, bool> ret_value = value.get_object();
// ...
// 根据 get_object 返回的 bool 值决定是否将对象加入“删除链”
if (ret_value.second || chain_delete_value) {
_delete_chain.push_back(ret_value.first);
}
_map[ret_key.first] = ret_value.first;
}
Map 内部有一个 _delete_chain,用来管理需要释放的内存。一个对象是否被加入这个“删除链”,取决于 get_object() 返回的 bool 值,或者调用 put 方法时传入的 chain_delete_value 参数。
现在,我们来看最关键的 ObjectValue::get_object 方法:
// ObjectValue::get_object 方法实现
pair<Object*, bool> ObjectValue::get_object() const {
switch (_type) {
// 我们的 tmp 对象类型是 OBJ
case OBJ: return pair<Object*, bool>(_value.obj, false);
case C_OBJ: return pair<Object*, bool>(_value.obj, false);
// 其他类型会 new 新对象并返回 true
case IVAL: return pair<Object*, bool>(new Integer(_value.ival), true);
// ...
default: return pair<Object*, bool>(NULL, false);
}
}
真相大白!当 _type 是 OBJ 时,get_object 方法返回的 bool 值是 false。这意味着它告诉调用者:“这个指针你不用管,我没有 new 新内存”。然而,我们的 tmp 对象恰恰是在外部 new 出来的。
由于 get_object() 返回 false,并且 put 方法调用时未指定 chain_delete_value(默认为 false),导致 if (ret_value.second || chain_delete_value) 条件不成立,tmp 对象最终没有被加入 _delete_chain。随着请求不断处理,无数个 ByteArray 对象被创建出来,却永远得不到释放,内存泄漏由此产生。
从被动应对到主动赋能:XRay 带来的排障新闭环
在追求系统稳定性的道路上,许多团队陷入了一个怪圈:为了解决问题,搜集更多的数据来获得更多的线索,为了收集更多的数据,增加更多的监控指标,搭建更复杂的 Dashboard,投入巨额预算购买更多的监控工具。结果这些工具带来了大量碎片化的信息,数据越来越多,信噪比却越来越低。工程师们依然要在“数据坟场”中翻找蛛丝马迹,淘金一样筛选有价值的信息。
这种模式的根本缺陷在于,它将技术问题如内存泄漏与商业成本:
- 一次内存泄漏告警,看似只是技术指标的波动,背后却是工程师宝贵时间的流失;
- 一次频繁的线上异常,不仅威胁系统稳定,更意味着业务中断的潜在风险;
- 持续高昂的监控投入,却换不来相匹配的洞察产出。
说到底,这不是“数据太少”,而是“有用的答案太少”。真正高效的可观测性工具,应该像一把“手术刀”,直接切入问题根源,而不是再给团队一把“铁锹”,让大家在数据堆里没日没夜地挖。这正是下一代可观测性平台所要解决的核心矛盾:
- 从表象指标走向因果链条
- 从被动告警走向主动分析洞察
- 从消耗人力走向真正释放研发生产力
总结
在这个案例中,OpenResty XRay 展示了另一种方式:把复杂、漫长的过程,变成一个可复用的闭环。我们称之为 “诊断 → 规划 → 验证”。
- 精准切入: 传统方法是“多看点数据,也许能找到线索”。XRay 的方式则不同:通过火焰图等可视化工具,它直接指向问题所在,让团队在几分钟内就能看到根因。它提供的,不是更多的监控指标,而是关键的、能推动行动的洞察。
- 从确凿证据出发制定方案: 当知道问题精确落在某一行代码或某个 C/C++ 模块时,修复方案就能直奔主题。团队不需要反复试错,而是基于明确证据,快速形成清晰、有效的行动步骤。
- 立即验证,形成完整闭环: 修复上线后,XRay 可以再次分析,确认问题是否已彻底消除。这种快速验证机制,让整个过程真正闭环:诊断、行动、验证,环环相扣。
这种闭环能力带来的价值,已经远远超越了单一 Bug 的解决:
- 技术价值: 赋能团队以无侵入的方式,直达生产环境中的 C/C++ 模块,将复杂问题简单化、可视化。
- 商业价值:
- 保障业务稳定: 快速消除潜在故障,保障服务的高可用性。
- 提升研发效率: 将工程师从繁琐、低效的 Debugging 中解放出来,投入到更有价值的业务创新中。
- 优化资源成本: 避免因未知性能问题而进行的过度资源配置,实现真正的成本控制。
在这个数据过载的时代,技术团队需要的不再是更多监控面板,而是一种更智能、更可信赖的方式,帮他们在最短时间内找到问题、解决问题,这才是可观测性的真正价值所在。
关于 OpenResty XRay
OpenResty XRay 是一款动态追踪产品,它可以自动分析运行中的应用,以解决性能问题、行为问题和安全漏洞,并提供可行的建议。在底层实现上,OpenResty XRay 由我们的 Y 语言驱动,可以在不同环境下支持多种不同的运行时,如 Stap+、eBPF+、GDB 和 ODB。
关于作者
章亦春是开源 OpenResty® 项目创始人兼 OpenResty Inc. 公司 CEO 和创始人。
章亦春(Github ID: agentzh),生于中国江苏,现定居美国湾区。他是中国早期开源技术和文化的倡导者和领军人物,曾供职于多家国际知名的高科技企业,如 Cloudflare、雅虎、阿里巴巴, 是 “边缘计算“、”动态追踪 “和 “机器编程 “的先驱,拥有超过 22 年的编程及 16 年的开源经验。作为拥有超过 4000 万全球域名用户的开源项目的领导者。他基于其 OpenResty® 开源项目打造的高科技企业 OpenResty Inc. 位于美国硅谷中心。其主打的两个产品 OpenResty XRay(利用动态追踪技术的非侵入式的故障剖析和排除工具)和 OpenResty Edge(最适合微服务和分布式流量的全能型网关软件),广受全球众多上市及大型企业青睐。在 OpenResty 以外,章亦春为多个开源项目贡献了累计超过百万行代码,其中包括,Linux 内核、Nginx、LuaJIT、GDB、SystemTap、LLVM、Perl 等,并编写过 60 多个开源软件库。
关注我们
如果您喜欢本文,欢迎关注我们 OpenResty Inc. 公司的博客网站 。也欢迎扫码关注我们的微信公众号:

翻译
我们提供了英文版原文和中译版(本文)。我们也欢迎读者提供其他语言的翻译版本,只要是全文翻译不带省略,我们都将会考虑采用,非常感谢!
相关文章
OpenResty XRay Apr 4, 2024

OpenResty XRay Jun 27, 2023

OpenResty XRay Nov 19, 2020

OpenResty XRay Oct 9, 2025

OpenResty XRay Sep 24, 2025

















