LuaJIT GC64 模式
OpenResty® 使用 LuaJIT 作为主要的计算引擎,用户也主要使用 Lua 语言来编写应用,即使是那些非常复杂的应用。在 64 位系统(包括 x86_64)上,LuaJIT 垃圾回收器能管理的内存最大只有 2GB 一直为社区所诟病。所幸 LuaJIT1 官方在 2016 年引入了 “GC64” 模式,这使得这个上限可以达到 128 TB(也就是低 47 位的地址空间),这也就意味着可以不受限制的跑在当今主流的个人电脑和服务器上了。在过去的两年里,GC64 模式已经足够成熟,所以我们决定在 x84_64 体系结构上也默认开启 GC64 模式,就像在 ARM64(或者 AArch64)体系结构上一样。这篇文章将简要介绍过去老的内存限制原因,以及新的 GC64 模式。
老的内存限制
官方的 LuaJIT 在 x86_64 体系结构上默认使用 “x64” 模式2,OpenResty 1.13.6.2 之前在 x86_64 体系上也默认使用这个模式。这个模式下 LuaJIT 垃圾回收器只能使用低 31 位的地址空间,这也就意味着最多能管理 2 GB 内存。
何时会碰到这个内存限制
那么什么时候会碰到这个 2 GB 的内存限制呢,我们很容易用一个小的 Lua 脚本来复现
-- File grow.lua
local tb = {}
local i = 0
local s = string.rep("a", 1024 * 1024)
while true do
i = i + 1
tb[i] = s .. i
print(collectgarbage("count"), " KB")
end
这个脚本里有一个 while 无限循环,不断地创建新的 Lua 字符串,并插入到一个 Lua table 里(为了防止 Lua 垃圾回收器回收它们)。每一次循环迭代都会创建一个 1MB 多的 Lua 字符串,并用 Lua 标准的 API 函数 collectgabarge 来输出当前由 Lua 垃圾回收器(GC)所管理的内存总大小。另外,值得一提的是,顶层作用域的 Lua table 变量 tb 也会持续生长,所以也会不断地消耗更多内存,虽然比那些 Lua 字符串消耗的要小得多。
我们可以简单地使用 OpenResty 提供的 resty 命令来跑这个脚本,比如:
$ resty grow.lua
4181.08984375 KB
5205.6767578125 KB
6229.869140625 KB
6229.66796875 KB
8277.4013671875 KB
9301.5546875 KB
10325.741210938 KB
...
2003241.1367188 KB
2004265.3320313 KB
2005289.5273438 KB
2006313.7226563 KB
2007337.9179688 KB
$
这次我们使用 “x64” 模式来编译 OpenResty。显然,在 Lua 垃圾回收器管理的内存接近 2GB 的时候,resty 工具就退出了。实际上是进程崩溃了。我们可以察看 shell 的返回值:
$ echo $?
134
使用 luajit 命令来跑这个脚本,我们可以看到更详细的崩溃错误信息:
$ /usr/local/openresty/luajit/bin/luajit grow.lua
4181.08984375 KB
5205.6767578125 KB
6229.869140625 KB
6229.66796875 KB
8277.4013671875 KB
...
2053220.5429688 KB
2054244.5634766 KB
2055268.5839844 KB
2056292.6044922 KB
2057316.625 KB
PANIC: unprotected error in call to Lua API (not enough memory)
这证实了我们确实触及到内存上限。
内存限制是每进程的
OpenResty 继承了 Nginx 的多进程模型来充分利用单机的多个 CPU 核,所以每个 Nginx worker 进程都有它自己独立的地址空间。因此,这个 2 GB 的限制也只是每一个独立的 Nginx worker 进程级别的。假如一个 OpenResty/Nginx 服务有 12 个 worker 进程的话,那么这个总的内存限制将是 2 * 12 = 24 GB。这也是为什么这么多年来,这个限制并没有给大型的 OpenResty 应用带来太多的问题,甚至大部分的 OpenResty 用户还不知道有这个限制。
然而,这个内存限制并不是每 LuaJIT 虚拟机(VM)级别的。比如,同一个 Nginx 进程内,ngx_stream_lua_module 和 ngx_http_lua_module 都创建了他们自己的 LuaJIT VM 实例,但是并不意味着这两个 LuaJIT VM 分别可以最多管理 2GB 内存,而是这两个 LuaJIT VM 加起来最多管理 2GB 的内存。因为这个内存限制是受限于地址空间,LuaJIT 的 GC 管理器只能使用低 31 位的地址空间。这个地址空间是进程级别的。
GC 管理的内存
大多数的 Lua 层面的对象(比如,string、table、fucntion、userdata、cdata、thread、trace、upvalue 和 prototype)都是为 LuaJIT 的垃圾回收器(GC)所管理的。其中的 upvalue 和 prototype 对象一般为 function 对象所引用。这些都被统称为 “GC 对象”。这部分由 GC 管理的内存,只是 OpenResty 进程内多个不同分配器之一;关于它如何与 Nginx 核心和共享内存区并存,可参阅《OpenResty 和 Nginx 如何分配和管理内存》。
其他原始值,比如 number,boolean 和 light userdata 并不是被 GC 管理的。他们直接使用真实的值作来编码,在 LuaJIT 内部被称作 “TValue”(或者 tagged values)。在 LuaJIT 内部,TValue 总是 64 位的,即使是单精度浮点数也是 64 位的(LuaJIT 使用了 “NAN tagging” 的技术来实现如此的高效的)。这也是为什么通常情况下,同一个应用使用 LuaJIT 来运行,会比使用标准的 Lua 5.1 解释器来运行所占用的内存少很多3。
不由 GC 管理的内存
LuaJIT 的 cdata 数据类型比较特殊。如果是通过标准的 LuaJIT API 函数 ffi.new() 来创建的 cdata 对象,他是由 GC 来管理的。但是如果是通过 C 层面函数,比如 malloc() 和 mmap(),或者其他的 C 库函数来申请的内存,那么这些内存 不是 由 GC 管理的,也就不会受到这个 2 GB 的限制。我们可以用如下的 Lua 脚本来测试:
-- File big-malloc.lua
local ffi = require "ffi"
ffi.cdef[[
void *malloc(size_t size);
]]
local ptr = ffi.C.malloc(5 * 1024 * 1024 * 1024)
print(collectgarbage("count"), " KB")
这里我们使用 ffi 调用了标准的 C 库函数 malloc() 来申请 5 GB 的内存块,使用 “x64” 模式的 OpenResty 或者 LuaJIT 来运行这个脚本并不会崩溃。
$ resty big-malloc.lua
73.1298828125 KB
GC 管理的内存大小也只有 73 KB,很明显没有包括直接从系统申请的 5 GB 内存块。
然而,不被 GC 管理的内存也可能对 LuaJIT 的内存限制产生不利影响。这是为什么呢?因为这些内存也可能会在低 31 位的空间内。
在 Linux x86_64 系统上运行 mmap() 系统调用的时候,如果没有指定任何地址参数(或其他会影响到内存分配地址的参数),一般并不会使用到低 31 位的地址空间。然而使用像 sbrk() 这类的调用则几乎总是优先使用低地址空间。后者就会让 LuaJIT 的 GC 内存分配器所能使用的内存空间又缩小了。这是由 Linux 等操作系统的内存布局方式决定的:“堆” 总是从低位到高位向上生长。类似地,在 Linux 等系统上,程序的数据段总是使用低地址空间靠近起始的位置,所以数据段内的静态常量数据(比如常量 C 字符串的值)也会进一步挤压 LuaJIT 可用的低地址空间。
基于上述原因,在 x86_64 体系下,实际可供 LuaJIT 使用的地址空间可能还显著小于 2 GB。实际可用的空间大小,取决于应用程序自身具体在什么地址位置上,申请了多少数量的内存空间。社区的用户也曾向我们反馈过这样的问题:在 FreeBSD 上,Nginx 申请的共享内存区域4也会挤压 LuaJIT 能使用的低地址空间。另外也有用户报告说,当使用了 ngx_http_slice_module 这样的第三方模块的时候,LuaJIT 也更容易抛出内存不足的异常。
提升 x64 模式的内存上限到 4 GB
理论上来说,LuaJIT 在 x64 模式上的上限应该是 4 GB(也就是低 32 位地址空间)而不是 2 GB,而且在 i386 系统上 LuaJIT 也确实能充分利用低地址的 4GB 空间。因为 LuaJIT 内部的手写汇编代码,每当需要从 32 位地址指针值转换到 64 位的时候,都需要正确处理“符号位扩展”(sign extension)的问题,也就导致了这个上限只有 2 GB。而 i386 体系则不存在这个问题,因为一个 word 值始终是 32 位的。
尽管 4 GB 比 2 GB 大了一倍,不过还是有可能触发上述那些问题。所以 LuaJIT 的开发者决定开发一个新的 VM 模式,以便能够使用到 大得多 的地址空间,于是便诞生了 GC64 模式。值得一提的是,这个 GC64 模式也是 ARM64(Aarch64)体系结构上的唯一选择,因为在那里低地址空间很难申请到。
新的 GC64 模式
GC64 模式始于 2016 年,最先由 Peter Cawley 实现,然后由 Mike Pall 来整合。在过去的两年多里,已经修复了很多 bug,并且经过广泛的测试,证明它已经足够稳定用于生产环境了,所以 OpenResty 也将在 x86_64 体系上切换到这个新的 GC64 模式 (ARM64 上已经强制使用 GC64 模式了)。
在 GC64 模式下,原始的 Lua 变量(上面提到的 TValue)还是继续保持 64 位大小,我们不用担心新的模式下内存使用量会有明显的涨幅。但是,还是有一些数据类型会变大(从 32 位变成 64 位),比如 MRef 和 GCRef 这样的在 LuaJIT 内部很常见的 C 数据类型。所以,GC64 模式下,尽管内存占用不会多很多,但肯定会更大一些。
在 GC64 模式下,垃圾回收管理器已经能使用低 47 位地址空间,也就是 128 TB。这已经远超当今高端 PC 机的物理内存(通常 64GB 就可以算大内存的机器,AWS EC2 实例最大的内存也只有 12 TB)。这也意味着,GC64 模式在当今的现实世界里,其实算是没有内存限制。
如何开启 GC64 模式
如果从 LuaJIT 源码编译,可以这样开启5:
make XCFLAGS='-DLUAJIT_ENABLE_GC64'
如果从 1.13.6.2 版本 之前 的 OpenResty 源码安装,可以在 ./configure 脚本加上如下选项来开启:
-with-luajit-xcflags='-DLUAJIT_ENABLE_GC64'
从 OpenResty 1.15.8.1 开始已经默认在 x86_64 系统上开启 GC64,包括 OpenResty 官方提供的二进制包 也默认开启了。
性能影响
新的 GC64 模式将产生多大的影响呢,下面用我们的一些大 Lua 程序来测试一下
Edge 语言编译器
首先,我们使用 Edge 语言(也叫 “edgelang”)编译器来编译一些大的 WAF 模块,在 x64 模式下:
$ PATH=/opt/openresty-x64/bin:$PATH /bin/time ./bin/edgelang waf.edge >
/dev/null
0.73user 0.03system 0:00.77elapsed 99%CPU (0avgtext+0avgdata 119660maxresident)k
0inputs+0outputs (0major+33465minor)pagefaults 0swaps
用 edgelang 编译器把 waf.edge 编译为 Lua 代码,花费了 0.73s 的用户态时间,最大内存占用是 119660 KB,也就是 116.9MB。下面我们用 GC64 模式:
$ PATH=/opt/openresty-plus-gc64/bin:$PATH /bin/time ./bin/edgelang waf.edge
> /dev/null
0.70user 0.03system 0:00.74elapsed 99%CPU (0avgtext+0avgdata 133748maxresident)k
0inputs+0outputs (0major+35396minor)pagefaults 0swaps
最大内存占用是 133748 KB,也就是 130.6MB,只大了 11.1%。CPU 使用时间几乎是一样的,这一点区别可以当做测试误差。
Edge 语言编译器是基于 OpenResty 上纯 Lua 的实现,包括空行和注释一共有 83,315 行代码,两者模式下对应的 LuaJIT 字节码都是 1.8MB(尽管 x64 和 GC64 的字节码不兼容)。
Y 语言编译器
我们再试一下 Y 语言(也叫做 ylang)编译器,这也是基于 OpenResty 的纯 Lua 命令行程序。
ylang 编译器比 edgelang 编译器要更大一些,对应的 LuaJIT 字节码有 2.1 MB(两个模式都是)。
我们先用 x64 模式,把 ljfrace.y 工具编译为 systemtap+ 脚本:
$ PATH=/opt/openresty-x64/bin:$PATH /bin/time ./bin/ylang --stap --symtab
luajit.jl lftrace.y > /dev/null
1.30user 0.12system 0:01.42elapsed 99%CPU (0avgtext+0avgdata 401184maxresident)k
0inputs+240outputs (0major+116438minor)pagefaults 0swaps
花了 1.3s 的用户态时间,最多占用了 401184 KB 内存,下面试一下 GC64 模式:
$ PATH=/opt/openresty-gc64/bin:$PATH /bin/time ./bin/ylang --stap --symtab
luajit.jl lftrace.y > /dev/null
1.30user 0.11system 0:01.42elapsed 99%CPU (0avgtext+0avgdata 433948maxresident)k
0inputs+240outputs (0major+125591minor)pagefaults 0swaps
还是花了 1.3s 时间,以及 433948 KB。这次时间没有区别,内存也只多占用了 8.2%。
调试分析工具链
目前开源的动态分析工具,包括 openresty-systemtap-toolkit, stap++ 和 openresty-gdb-toolkit 几乎都不支持新的 GC64 模式,我们也不再维护这些针对 systemtap 和 gdb 的开源工具了。 我们的重心已经放到了 OpenResty XRay 平台及其 Y 语言编译器上。我们用标准 C 语言的超集(即 Y 语言)编写工具。Y 语言编译器可以将其编译为 Python 代码,并运行在 gdb 里,也可以编译为 stap+ 脚本用 systemtap+6 来运行(未来也会支持更多的后端,可以运行在更多的调试和动态追踪平台上)。我们几乎不用改动这些 Y 语言编写的工具,就可以直接支持 GC64 模式。这个得益于智能化的调试信息处理,以及 Y 语言使用的是 C 语言层面的表达方式。
如下是一个 GC64 模式下的 Openresty Lua 层面的火焰图,使用的是我们的 ylang 工具和 systemtap+。
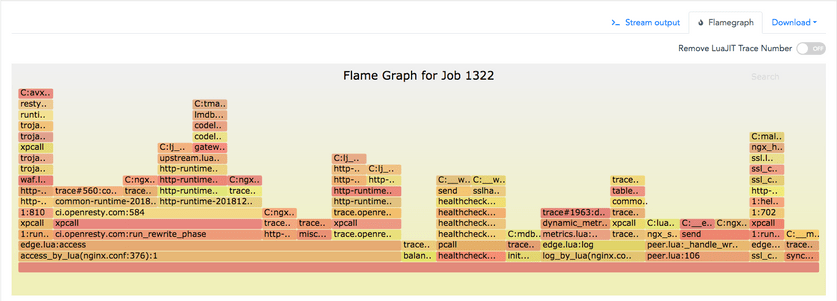
并且 ylang 编译器生成的 gdb 工具也可以用于分析 core dump 文件,比如:
(gdb) lbt 0 full
[builtin#128]
exit
test.lua:16
c = 3
d = 3.140000
e = true
k = nil
null = light userdata (void *) 0x0
test.lua:baz
test.lua:19
ffi = table: (GCtab *)\E0x[0-9a-fA-F]+\Q
cjson = table: (GCtab *)\E0x[0-9a-fA-F]+\Q
test.lua:0
ffi = table: (GCtab *)\E0x[0-9a-fA-F]+\Q
cjson = table: (GCtab *)\E0x[0-9a-fA-F]+
C:pmain
(gdb)
火焰图里的函数帧包含了 Lua 函数帧和 C 函数帧。
我们在 OpenResty XRay 里不仅提供了现成的基于 ylang 编写的动态追踪分析工具,也提供了在线编译器。我们可以使用 Y 语言轻松实现全新的分析工具。
LuaJIT 内建的性能分析器
从 2.1 版本开始,LuaJIT 官方就内建了虚拟机层面的性能分析器。这个自然可以继续在 GC64 模式下使用。然而,不同于 systemtap+ 这样的系统层面的动态追踪工具,它必须清空所有已经 JIT 编译过的 Lua 代码(在 LuaJIT 的术语里叫 “traces”),并且需要用特殊的性能分析模式重新进行 JIT 编译。因此,每次打开和关闭性能分析器,都会触发所有相关 Lua 代码重新开始 JIT 编译。这必然会修改当前进程里的很多状态(很容易有意外的副作用,或者极端 bug 的出现),并且在分析采样期间,也会有较高的性能损耗7。另外,目标 Lua 程序也需要提供一个特殊的 API 或者钩子来触发这样的性能分析模式,因此需要应用程序的专门配合,才能让内建性能分析器正确工作。然而,基于动态追踪技术的性能分析则完全无需 Lua 应用程序的任何配合,甚至不需要重启,或者使用特殊的编译选项。
结论
文本介绍了 LuaJIT 新的 GC64 模式,可以有效地取消原先 2GB 每进程的 GC 管理的内存上限。使用更多的内存的能力也意味着 OpenResty 应用自己需要更加小心内存使用量过大或内存泄漏之类的问题。幸运的是,OpenResty XRay 可以帮助我们快速分析和优化任意的 OpenResty 应用的内存使用。我们在一个新的系列文章中将会展开这个话题。
需要说明的是,本文讨论的是 LuaJIT 的内存上限。如果你的症状正好相反——GC 指标看起来很健康,但进程的 RSS 却持续增长,直到 OOM killer 出手——那是另一个问题,其根源在于 LuaJIT 默认的分配器从不把已释放的内存页归还给操作系统。相关分析以及分配器层面的修复方案,请参阅《修复 OpenResty 中 LuaJIT RSS 内存泄漏》。
延伸阅读
- 《OpenResty 和 Nginx 如何分配和管理内存》
- 《预编译 Lua 模块到 LuaJIT 字节码中以加快 OpenResty 启动速度》
- 《修复 OpenResty 中 LuaJIT RSS 内存泄漏:无需重启即可消除 OOM Kill》
关于 OpenResty XRay
OpenResty XRay 是由 OpenResty Inc. 公司提供的商业产品。我们使用此产品为我们的文章(比如本文)提供直观的图表演示和真实系统内部的统计数据。OpenResty XRay 可以在无需目标程序任何配合的情况下,帮助用户深入洞察其线上或者线下的各种软件系统的行为细节,有效地分析和定位各种性能问题、可靠性问题和安全问题。
有兴趣的朋友欢迎联系我们,申请免费试用。
关于作者
章亦春是开源 OpenResty® 项目创始人兼 OpenResty Inc. 公司 CEO 和创始人。
章亦春(Github ID: agentzh),生于中国江苏,现定居美国湾区。他是中国早期开源技术和文化的倡导者和领军人物,曾供职于多家国际知名的高科技企业,如 Cloudflare、雅虎、阿里巴巴, 是 “边缘计算“、”动态追踪 “和 “机器编程 “的先驱,拥有超过 22 年的编程及 16 年的开源经验。作为拥有超过 4000 万全球域名用户的开源项目的领导者。他基于其 OpenResty® 开源项目打造的高科技企业 OpenResty Inc. 位于美国硅谷中心。其主打的两个产品 OpenResty XRay(利用动态追踪技术的非侵入式的故障剖析和排除工具)和 OpenResty Edge(最适合微服务和分布式流量的全能型网关软件),广受全球众多上市及大型企业青睐。在 OpenResty 以外,章亦春为多个开源项目贡献了累计超过百万行代码,其中包括,Linux 内核、Nginx、LuaJIT、GDB、SystemTap、LLVM、Perl 等,并编写过 60 多个开源软件库。
关注我们
如果您喜欢本文,欢迎关注我们 OpenResty Inc. 公司的博客网站 。也欢迎扫码关注我们的微信公众号:

译文
我们提供了英文版原文和中译版(本文) 。我们也欢迎读者提供其他语言的翻译版本,只要是全文翻译不带省略,我们都将会考虑采用,非常感谢!
OpenResty 维护了我们自己的分支,这个分支里包含了一些高级特性以及针对 OpenResty 的特殊优化,这个分支会定期的从 官方 LuaJIT 同步。 ↩︎
从 2019 年 12 月 8 日开始,官方的 LuaJIT 也开始在 x86_64 系统上默认使用 GC 模式。 ↩︎
我们曾在真实的生产环境,观察到 LuaJIT 与标准 Lua 5.1 解释器之间的内存使用量,存在成倍的差别。 ↩︎
这些共享内存区域实际上是通过
mmap系统调用分配的。 ↩︎从 2019 年 12 月 8 日开始,官方 LuaJIT 在 x86_64 上已默认开启 GC64 模式。 ↩︎
systemtap+ 是由 OpenResty Inc. 大大增加和优化过的 systemtap。 ↩︎
Java 世界的 BTrace 工具也有类似的问题和局限。 ↩︎
相关文章
OpenResty XRay Aug 4, 2020

OpenResty XRay Jan 21, 2020

OpenResty XRay Nov 19, 2020

OpenResty XRay Aug 10, 2020

OpenResty XRay Dec 4, 2025
















